Text-based answer-first content (Chapter 7) covers one retrieval surface. Format matters. AI systems pull from many formats and weight them differently across platforms, because retrieval ranks the format that best fits the query rather than defaulting to text, which means brands publishing only in one format leave large citation space on the table. BrightEdge's October 2025 study measured YouTube cited in 29.5% of Google AI Overviews. Multimodal retrieval reached production grade in 2025 across all major AI tools. Images, video, audio, and structured data each carry weight. This chapter covers the format mix and the by-platform order. The video-with-transcript pattern comes next, followed by image and audio practices and structured-data setup. One section maps the multi-format patterns on a single page. Worked examples that build on text work close the chapter.
Why This Technique Matters
AI Search systems pull and blend across formats. A single user query about a niche tool can produce a mixed response that cites a Reddit thread, a YouTube transcript, a vendor comparison table, an analyst chart, and a podcast clip in the same answer. The model picks based on which content best fits the query. Format type is not the filter. Fit is. Brands that publish only text give up every citation slot where a non-text format wins on fit.
The impact is large. BrightEdge measured YouTube cited in 29.5% of Google AI Overview responses. Roughly three in ten AIO cites across topics come from video. The Profound October 2025 data showed YouTube as the most-cited domain across one billion AI cites. It beat Reddit. It beat any single news outlet. Buyers research some topics through video. For these topics, video cite share rises above the 29.5% line. Common ones are product reviews, how-to content, software demos, and gear selection.
The other format surfaces matter at smaller but real scales. Image content (charts, diagrams, screenshots) earns retrieval through multimodal RAG when paired with descriptive text. Audio content (podcasts) earns cites through show-note transcripts indexed with the text. Structured data (tables, schema-marked content, machine-readable specs) earns cites when the data extracts cleanly.
The cost of a one-format play grows with brand age. A new brand running text-only can still earn solid cites. The lever is content quality. A mature brand running text-only faces a harder problem. Rivals who built video and tables years earlier now hold compounding gains. These take sustained work to close. The multi-format push is a long-horizon investment. It is not a quarterly campaign.
The Five-Format Surface Map
Multi-format coverage breaks into five surface types. Most brands work three or four at real scale. All five is rarely worth the load unless the brand is at enterprise scale.

Text on Owned Domain
The base surface is covered in Chapter 7. Every other format builds on text rather than replacing it. The text surface carries the answer-first build. It carries the structural elements (lists, tables, FAQ) and the schema-marked content. Brands without a strong text base cannot use multi-format growth well. The text holds the supporting context AI systems need to retrieve non-text formats.
Investment baseline: the content program in Chapters 4 through 9. Multi-format work builds on this baseline. Without it, the multi-format work earns minimal lift.
Video
This is the highest-impact non-text format. YouTube is the top platform for AI Search cites. Google indexes YouTube transcripts. They surface in AIO replies at the 29.5% rate BrightEdge measured. Vimeo, Wistia, and self-hosted video earn less cite share. The fix is to pair them with on-page transcripts that match YouTube's auto-transcript indexing.
Three video types drive cite share in B2B. Short product or solution explainers show how the product solves a buyer problem. Decision-support videos walk through vendor evaluation criteria. Concise case studies and customer voice videos feature named customers explaining outcomes. B2C adds product demos, unboxings, and how-to tutorials at higher volume. The underlying discipline carries over from video SEO best practices, now applied to a retrieval surface rather than a results page.
The setup rules for cite-earning video are clear. Use YouTube hosting. The auto-transcript is the cite surface. Write a descriptive title. Use the buyer's actual query phrasing where natural. Write a 200-to-500-word description that covers the key points. Add chapter markers at major topic shifts. Add a pinned comment with key links and timestamps. Verify and edit closed captions. Auto-transcripts have errors that affect retrieval.
Production effort varies with the quality tier and with whether the operator is on camera. Talking-head with slide overlay still works for AI cites. The content is what gets retrieved, not the cinematography. Higher-end production matters more for brand image than for cite share.
Images and Diagrams
Image content carries key info that multimodal RAG can retrieve when paired with text. Charts, diagrams, screenshots, comparison visuals, and infographics all count. The retrieval path needs supporting text. The text makes the image's content clear. Alt text describes what the image shows. The caption sums it up. The text near the image cites it where it fits.
The setup is simple. Every key image on a page carries descriptive alt text. It is not a filename. It is not a keyword-stuffed phrase. Images with a caption carry both alt and caption. The two play different roles. Alt is for access and retrieval. Caption is for human reader context. Filenames matter less than alt text. They still feed retrieval. Use descriptive filenames over generic ones as the default.
The dual-format rule from Chapter 5 applies here. Stats, frameworks, and key claims in a chart or infographic also need to appear in parsable HTML next to the image. The visual serves the human reader. The HTML serves the retrieval index. Pages that show stats only in image form earn near-zero AI cites. Visual quality does not change that.
Proper alt and caption work adds little beyond operator and editor time during content build. Custom diagrams and infographics carry their own production effort. The cite lift usually justifies that effort for content that benefits from a visual.
Structured Data
Tables, schema-marked content, machine-readable specs, and database-style content all retrieve cleanly as separate units. The structure itself is the lever. Comparison tables on vendor evaluation queries, spec tables on product pages, pricing tables, and data tables all over-index in AI cites. They beat the same content shown as prose.
The setup is simple. Where content is comparative or listed, use a table or list rather than prose. Tables carry HTML structure (thead, tbody, th, td) that retrieval reads. Tables built as styled divs or via CSS positioning underperform. The semantic markup signals are missing. Schema markup (Product, Offer, Specification, PriceSpecification) backs up the table's machine read; the same structured data fundamentals that earn rich results also feed the discovery layer AI retrieval pulls from.
Chapter 9 covers schema and semantic HTML in detail. The structured-data work overlaps with the answer-first work in Chapter 7. Lists and tables are both answer-first patterns and structured-data patterns.
Audio
Audio carries cite share through show notes, transcripts, and chapter markers. These get indexed with the audio file. The audio itself is not directly retrieved by most AI systems today. The text artifacts around the audio carry the cite weight.
Two pathways exist for audio coverage. The first is owned podcast production. The brand runs its own podcast with show notes, transcripts, and chapter markers. The second is podcast appearances on third-party shows (covered in Chapter 3). Most mid-market brands focus on appearances before owned production. The production cost is large. Appearance ROI builds up faster. Brands with operator-led content programs and content scale start owned podcasts once that base is established.
The setup rules for cite-earning podcast content are clear. Post full transcripts on the brand's owned domain. Do not rely on the podcast platform alone. Show notes should sum up key points with timestamps. Add chapter markers at major topic shifts. When guests are on, link to the operator's bio page. Cross-link from episode pages back to the right text content on owned domain.
Owned podcast production is a significant ongoing operation. It covers host, production, editing, post-production transcripts and notes, and distribution. Appearances ask for operator time only.
The Format Hierarchy by AI Platform
Each AI system weights formats differently. The best format mix shifts based on which platforms the brand most needs to win.
- ChatGPT. Heavy weight on text with structural parts (lists, tables, FAQ blocks). Some video weight through YouTube indexing. Multimodal image work is new but shows up less in replies. Audio is mostly indirect through transcripts.
- Claude. Text-leaning. Strong weight on method and source-cited content. Image and PDF support is strong in the model. Claude's retrieval shows fewer non-text cites than ChatGPT or AIO.
- Perplexity. Mixes text, video transcripts, Reddit, and community content. YouTube cites show up often when the video transcript fits the query well. Image content shows up inline more than on other platforms.
- Google AI Overviews. Highest video cite rate (29.5% per BrightEdge October 2025). Strong reuse from organic Google results across all formats. Tables, FAQ content, and video snippets all over-index. Image retrieval runs through Google's image index.
- Gemini. Native multimodal tools with the strongest image and video retrieval of any major AI system. Brands with strong visual content show up in Gemini more than on other platforms.
- Microsoft Copilot. Bing-indexed text leads. Video retrieval runs through the Bing video index. LinkedIn ties bring LinkedIn video into the cite pool. Image retrieval runs through the Bing image index.
The cross-platform pattern is clear. Text is universal. Video over-indexes in AIO and Gemini. Structured data over-indexes in ChatGPT. Image retrieval over-indexes in Gemini and Perplexity. Audio over-indexes in Perplexity through transcript matching.
The Format-Platform Citation Matrix
The format-by-platform breakdown reads cleanest as a matrix. The matrix below estimates relative citation weight from each format on each AI platform, scored 0 to 10. The scores come from Searchbloom's measured engagements across mid-market B2B and B2C categories, cross-referenced with BrightEdge and AirOps published data. Use the matrix to prioritize the format mix when capacity constrains the program to two or three formats.
Reading the matrix. Answer-first text scores 8 to 10 on every platform; it is the universal foundation. Video scores 9 to 10 on AIO and Gemini but drops to 4 to 6 on Claude and Copilot; AIO-priority brands should over-invest in video. Comparison tables and FAQ score 7 to 10 on every platform when paired with schema; they are the second-most universal format after text. Images peak on Gemini at 10 but drop to 5 on ChatGPT and Copilot; Gemini-priority brands should over-invest in image content with descriptive alt. Podcasts score modestly across all platforms; they earn citation through transcript indexing rather than direct retrieval. Their compound effect through entity reinforcement (Chapter 6) is the strategic argument, not direct citation lift.

The matrix updates as platforms evolve. ChatGPT image retrieval is improving. Claude video retrieval is improving. Refresh the matrix annually. Use it to make the format-allocation call when the brand cannot resource all formats.
Multi-Format Presentation on a Single Page
The high-impact pattern combines many formats on a single page. It beats spreading formats across pages. Take a page covering "how to evaluate CRM platforms for mid-market sales teams." It works best with five parts. Answer-first text (Chapter 7). An embedded video walking through the framework. A comparison table of top platforms. A method diagram. An FAQ section. The page becomes a multi-format retrieval surface that AI systems can cite from in many ways.
The build order is clear. Open with answer-first text in the first 200 words. Place an embedded video near the top of the body. This serves visual learners and AIO video retrieval. Add a comparison table for the decision-support content. Include diagrams or screenshots where the visual adds clarity. Use body text for the depth that text handles best. Close with an FAQ section that uses FAQPage schema. Each format covers a different reader type and a different retrieval signal.
The pattern grows the cite surface area per page a lot. The same content as text-only earns text cites only. The multi-format version earns text, video, table-based comparison, and FAQ cites. AirOps measured pages with three or four format types earning 2 to 4 times the total cite share of single-format pages at the same content levels.
The Video-with-Transcript Pattern
This is the reliable workflow for video that earns AI cites. Six steps work as a checklist on every published video.

Step 1: Script the video as answer-first content. The opening of the video holds the answer to the video's main question. The rest adds depth, examples, and caveats. The pattern matches Chapter 7's text build. The content fits the same retrieval rules whether in text or video.
Step 2: Publish to YouTube with discoverable metadata. Phrase the title as the buyer's actual question. Write a 200-to-500-word description covering the key points. Add tags relevant to the category. Pick a thumbnail that signals the topic. Pick the category right.
Step 3: Verify and edit the auto-transcript. YouTube's auto-transcripts have accuracy issues. They affect both human viewing and AI retrieval. Budget focused editing time for the transcript. Fix terms, named entities, and any technical content the auto-system misheard. Brand names, product names, and category words all need manual fixes. The Transcript Quality Threshold below names the accuracy bands and their impact on retrieval.
Step 4: Add chapter markers at major shifts. Chapter markers act as section headings for video content. AI systems pull chapter markers as separate retrieval signals. A longer video with no chapters retrieves as one big unit. The same video with 6 chapters retrieves as 6 separate units.
Step 5: Embed on owned-domain page with supporting context. Embed the video on a page covering the same topic. The page gives AI systems the supporting text context they need. The embed plus the page produce two retrieval surfaces. The first is the standalone video on YouTube. The second is the video plus surrounding text on owned domain.
Step 6: Cross-link from related content. The video earns more retrieval share when linked from related pages on the brand's domain. Two or three internal links from related pages to the video's page raise the video's retrieval odds. There is no added build cost.
The Transcript Quality Threshold
Transcript accuracy is not binary. The quality threshold for AI retrieval sits at a specific level. Most brands either over-invest (manual transcription from scratch) or under-invest (raw YouTube auto-transcript). The right pattern is targeted editing to clear the threshold. Word Error Rate (WER) is the standard accuracy metric. It measures the fraction of words a transcript got wrong relative to the spoken audio. Reading bands:

The targeted editing pattern that hits WER 3 to 8% efficiently: open the auto-transcript, search for each brand name, product name, and named expert appearing in the video, correct each instance. Search for the 5 to 10 most important technical terms covered in the video. Correct each instance. Spot-check the chapter-marker timestamps against the video. Fix any timestamps that are noticeably off. The pattern catches 80% of the errors that matter for retrieval. It skips the 20% of errors (common-word substitutions in non-load-bearing sentences) that do not affect AI extraction. The targeted edit is the highest-ROI transcript work the brand can do.
Repurposing One Substantive Asset Across All Five Formats
The highest-impact pattern is repurposing one strong asset across all five surface types. The launch is coordinated. The asset is the source. The formats are the surfaces. This multi-format build is one discipline within Corpus Engineering: treating the brand's full body of content as one engineered corpus that AI retrieval reads across formats rather than a set of isolated pages. The pattern earns outsized cite lift versus the same source in text-only. Each format addresses a different retrieval method and a different AI platform's strengths. The build is larger than text-only. The cite lift across platforms usually pays back the added effort over time when the source asset is truly strong.
The strong source is the prereq. The pattern does not rescue thin content. A 1,200-word blog post with no original research or framework cannot be repurposed across five formats well. The base content is not enough to support the build. The AI retrieval signal will not improve much. The pattern works when the source asset is a 5,000-to-12,000-word document. It needs original research, an original framework, or original analysis. Chapter 4 (Original Source Asset Development) covers the content rules. This section covers what to do with the content once it exists.
Step 1: The source asset. This is usually a 5,000-to-12,000-word document. It adds net-new information gain (Chapter 5) through original research, a framework, or analysis. The document exists as a working artifact before any format-specific build starts. The author or research team finalizes the content, the charts, the comparison tables, and the framework diagrams. Every other format comes from this source. The effort scales with the research scope. A full original research study is a major undertaking; a framework launch is lighter.
Step 2: Text on owned domain. Publish the source as a long-form canonical page. Use the answer-first pattern in Chapter 7. The parts include a TLDR section in the first 200 words. Use question-based headings throughout. Add a method section explaining how the research was done. Add an FAQ section near the end. Add schema markup for the article and the FAQ. Send an IndexNow note at publish time (Chapter 12) so the AI retrieval indexes pick up the page right away. Build cost: one author plus one editor, a contained block of work. The text base is the canonical reference every other format will cite back to.
Step 3: Video. A producer creates a concise summary video. The video walks through the key findings with the named author on camera. The format is summary-level rather than full coverage. The goal is to drive viewers back to the full source for depth. The video also stands on its own as a YouTube cite surface. Publish it to YouTube with an edited transcript, chapter markers at the key findings, descriptive metadata, and a thumbnail that signals the topic. Embed the same video on the owned-domain text page. The page becomes a multi-format retrieval surface. Allow lead time for scheduling the author, filming, editing, and transcript fixes.
Each format addresses a different retrieval method and a different AI platform's strengths.
Step 4: Image and chart suite. A designer makes 4 to 8 chart images. The charts visualize the source's data findings. Add 1 or 2 framework diagrams if the source has a framework. Each chart includes descriptive alt text covering what the chart shows. Each chart is paired with a parsable HTML table that shows the same data. This follows the dual-format rule from Chapter 5. The HTML tables earn cites directly. The charts earn multimodal retrieval cites on Gemini and Perplexity. Those platforms have the strongest image retrieval. The framework diagrams get OG-image treatment for social. The design effort depends on quality tier and chart count.
Step 5: Audio. The named author records a full-length podcast episode. The author discusses the source asset with a host. The host can be an internal team member, an outside podcast partner, or the host of an existing show in the category. The episode goes live on the brand's owned domain as a page. The page has a full transcript, chapter markers, and show notes that sum up the key points with timestamps. The episode also goes to the major podcast platforms: Apple Podcasts, Spotify, Google Podcasts, and YouTube as a video podcast where it fits. The owned-domain transcript page carries the AI cite weight. The platform distribution carries the audience-reach weight. The editing and transcript fixes are a contained block of work.
Step 6: Structured data. The source's key tables and comparison data go live as HTML tables with schema markup. Use Dataset schema, Table schema, or Product schema based on what the data shows. The structured-data surface earns cites on ChatGPT and AIO. Those platforms over-index on structural retrieval signals. The setup includes thead and tbody markup, descriptive th elements, semantic table captions, and the schema chain linking the table to the source document. Build cost: a modest block of developer time. The work covers the table markup plus schema generation and validation.
The platform-by-platform cite lift pattern has a clear shape. AIO earns cites through the long-form text page with the embedded charts. The chart retrieval and the text retrieval both surface the source. Perplexity earns cites through the podcast plus the owned-domain links. The podcast transcript matches well to the chat-style queries Perplexity favors. ChatGPT earns cites through the structured comparison tables and the FAQ section. The structural signals match ChatGPT's taste for parsable content. Gemini earns cites through the multimodal chart retrieval. The chart images plus their alt text and HTML tables produce strong multimodal matches. Copilot earns cites through the LinkedIn-shared long-form posts that link the source. The LinkedIn-Bing tie-in brings the LinkedIn content surface into the cite pool.
The five-format launch is a substantially larger build than a text-only page. The cite lift across AI platforms compounds well past what the text-only version earns. The exact ratio depends on category. The added retrieval surface pays back the added effort. The pattern is most effective when the source asset is truly strong. Thinner sources do not justify the launch.
The cadence question has a realistic answer. How often can a brand run the full multi-format launch? Once per quarter for the flagship asset is the practical max for most mid-market brands. The constraint is not production capacity. It is the strong-source pipeline. Producing four truly original research studies or framework launches per year is a heavy research load. Brands trying a higher cadence usually compromise on content. That defeats the pattern. Between the quarterly full launches, the working cadence is lighter repurposes. Text plus one second format like video or podcast works on a frequent rolling cadence. The lighter repurposes hold the multi-format presence between flagship launches. They do not exhaust the build pipeline.
The team needed to run the cadence depends on brand scale. A mid-market brand running quarterly full launches needs four roles. A content lead. A video producer (full-time or contracted). A designer (usually contracted). An audio producer (usually contracted). The content lead owns the source asset build and the long-form text page. The rest of the team makes the second-tier formats from the source.
Brands trying to run the cadence with fewer roles consolidate. The content lead might also make the podcast. But this hurts execution quality somewhere. The content-first rule holds across every format. Stretched teams make thin second formats. These do not earn the cite lift the pattern depends on.
The role of the named author across the launch is a separate planning point. The author appears on camera for the summary video. The author is on microphone for the podcast episode. The author is in the byline on the long-form text page. The total author commitment is modest but real. This covers the source asset build, the video filming, the podcast recording, and the distribution motion. The distribution motion includes LinkedIn posts, internal sales-team enablement, and partner amplification calls.
Brands without a credible named author cannot run the pattern as designed. The author byline produces the entity density Chapter 10 covers. The named-expert pattern depends on the author actually appearing across the formats. Ghostwriting from behind the brand does not work. The named author is usually the founder, the head of research, or a known subject-matter expert on the team. A generic content marketer does not produce the same lift.
The named-expert pattern depends on the author actually appearing across the formats.
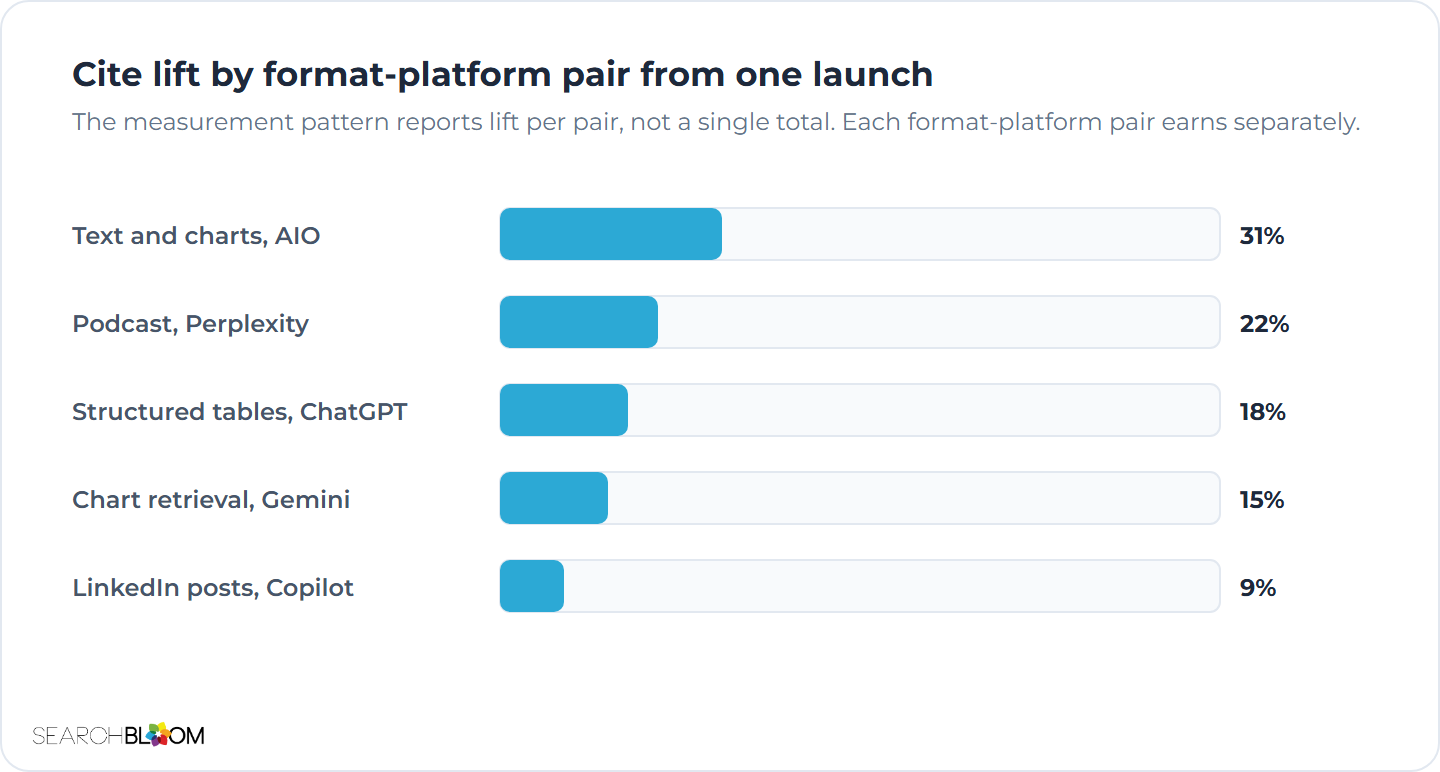
The measurement pattern tracks cite share by format separately. It does not report a single total. The strongest lift tends to come from the long-form text page and its embedded charts on AIO. The podcast adds share on Perplexity, where the transcript matches the chat-style queries that platform favors. The structured comparison tables add share on ChatGPT. The chart retrieval adds share on Gemini. The LinkedIn distribution adds share on Copilot through the LinkedIn-Bing tie-in. The split-out reporting lets the brand see which format-platform pairs produced the strongest lift. This shapes the next flagship launch's effort mix. Chapter 13 covers the measurement cadence in operational detail.
The sequencing inside the launch window matters as much as the format mix itself. Publishing all five formats at once produces less compounding lift than the staggered release. Each later format cites and links back to the prior formats. This builds internal cite density. The AI retrieval surfaces read this as topical authority. The video description links the long-form text page. The podcast show notes link both the text page and the video. The structured tables link to the long-form source. The LinkedIn posts link the underlying research. Each cross-link backs up the topical cluster (Chapter 6). It signals to AI systems that the source is the canonical reference in the topic. Brands that publish all five formats simultaneously give up this internal cite density. They earn meaningfully less retrieval lift across the platform mix.
The pattern also handles common build breakdowns well. When the podcast slips because the host has a scheduling conflict, the launch does not stall. The text page, the video, the charts, and the structured tables all keep earning cites while the podcast catches up. When the designer needs an extra cycle on a framework diagram, the charts can go live in two waves. They do not block the full launch. The staggered window is the target cadence rather than a hard deadline. What matters is the coordinated launch motion across formats. The exact spacing between formats does not matter.
Industry Variants
Ben Wills's March 2026 research on 145 industries informed the format-mix biases by category.
- Visual product categories (beauty, apparel, furniture, food). Image and video content over-index. Single-product pages benefit from many images per product, short product videos, and lifestyle imagery with descriptive captions, which is why e-commerce SEO in these categories leans hard on the visual surfaces. The text foundation is still required for AI retrieval to interpret the visuals.
- Technical product categories (developer tools, hardware, scientific equipment). Spec tables and technical diagrams over-index. Video walkthroughs of features and integration patterns earn citations at high rates. Code samples in semantic HTML carry citation weight for the technical buyer persona.
- Service categories (consulting, agencies, professional services). Operator-led video and audio over-index. The buyer wants to evaluate the practitioner. Text frameworks plus operator-on-camera explainer videos plus podcast appearances form the optimal mix.
- Local services (home services, healthcare providers, legal practices). Location-based structured data, customer review video testimonials, and before-and-after imagery over-index, and the format mix here pairs closely with the location-signal work in local SEO. The dual-format rule applies hard. Visuals need text descriptions for AI retrieval.
- Information-product categories (publishing, education, training). Audio and long-form video over-index for educational content. Course pages with embedded preview videos plus structured curriculum tables earn citations across many AI platforms.
Common Mistakes That Defeat Multi-Format Coverage
1. Video without transcripts. The most common failure mode. The brand produces video and uploads it without proper transcripts. AI retrieval cannot extract the video's substance. Counter-test: do your top 10 videos have edited (not auto-generated) transcripts on YouTube and on the embedding page?
2. Image-only statistics and frameworks. Charts and diagrams carry key numeric content without parsable HTML alongside. AI systems cannot run OCR on images during retrieval. Counter-test: pick a statistic that appears as a chart on your top pages. Can the underlying number be extracted from page text without seeing the image?
3. Filename alt text. Images uploaded with generic alt text or filenames used as alt text ("DSC_0421.jpg" or "image001"). The retrieval signal is absent. Counter-test: spot-check 20 images across your top pages. What percentage carry descriptive alt text?
4. Spreading formats across pages instead of combining them. Video on one page, comparison table on another, FAQ on a third. The single-format pages each earn less retrieval than a multi-format combined page would. Counter-test: do your highest-value pages combine three or four format types? Or are formats fragmented?
5. Owned-podcast investment before owned-text foundation. Brands jumping to podcast production before the text content base supports it produce thin audio. Thin audio earns minimal citations. Counter-test: is the text foundation strong before podcast production starts?
6. Vimeo or self-hosted video without YouTube companions. Vimeo and self-hosted video earn less AI citation share than YouTube. The indexing pathways differ. Counter-test: where do your videos live? Is YouTube part of the distribution?
7. No chapter markers on long video. Longer videos without chapter markers retrieve as one unit. They should retrieve as many sub-units. Counter-test: pick one of your longer videos. How many chapter markers does it have?
8. Production-quality optimization at the expense of substance. Brands invest heavily in cinematography. They neglect the answer-first content the video delivers. Counter-test: would the video earn citations if produced as a simple talking-head with slides? Or does it depend on high-end production to be useful?
Questions & Answers
Why does multi-format coverage matter? AI systems retrieve across format types and weight them differently. BrightEdge October 2025: YouTube cited in 29.5% of Google AIO responses. Brands publishing in one format leave large citation surface area unaddressed.
How does video earn AI citations? Through three artifacts. The YouTube transcript indexed by Google. The video description, title, and chapter markers. The supporting content on the embedding page on owned domain. Videos without transcripts earn minimal citations.
What is the right format mix? Text foundation. YouTube video with transcripts. Images with descriptive alt. Structured data (tables, schema) wherever it fits. Audio belongs in the mix when the brand has a publishing motion. If not, use appearances on third-party podcasts.
Are images retrievable by AI? Yes, via multimodal RAG, with caveats. Alt text, caption, surrounding text, and filename all feed retrieval. Visual content without supporting text remains invisible. The retrieval index relies on text signals.
Is video more important for B2B or B2C? Important for both, with different patterns. B2C needs higher volume. B2B needs fewer videos with deeper substance. Both benefit from the YouTube AIO citation pattern.
What is multimodal RAG? Retrieval systems that pull in images, video frames, and audio clips alongside text as discrete units. They reached production grade across major AI platforms in 2025.
Should every blog post include a video? No. 20 to 40% of pages on a mid-market site benefit from video. Forcing it onto every page produces thin video that under-performs.
How does audio fit? Two pathways. Owned podcast production with transcripts. Podcast appearances on third-party shows (Chapter 3). Most mid-market brands focus on appearances before owned production.
