
Updated May 6, 2026
“Information Gain or Net New Information gain is the single highest-leverage content move we’ve measured at Searchbloom and it produces an average 400% lift in blended Traditional & AI search visibility.”
~ Cody C. Jensen, CEO, Searchbloom
Information gain in traditional and AI search has a measurable formula, a quantifiable threshold, and the move quoted above is an example of a technique you can use to provide net new information gain. Most articles on the subject describe none of those things. In this article, my aim is to not only describe exactly what Net New Information Gain is, but also how to measure it and the techniques in which you can leverage to build it into your content pipeline process, whilst measuring and scoring it along the way. In short, I aim to provide net new information gain on the vector space of information gain itself. i.e., This article’s embedding should land in a meaningfully different region of vector space than existing content on the term “information gain” by applying information gain techniques within the article itself.
Many articles on this subject cite the same Google patent and misinterpret it. This is what Google means when they say “commodity content”: you’re recycling content that has already been said, just saying it in a different way and stuffing keywords into it. They summarize the same secondhand four-strategy framing and stop. None of them tell you how much information gain you actually need, how to measure it, or which moves produce the biggest lift. Those are the three questions every operator has, and in this article, I will answer all three. I introduce a framework we use at Searchbloom called Information Gain Density, a measurement formula we call the Information Gain Score, and the single highest-leverage content move we have measured across our partner-clients.
TL;DR
- Information gain is the principle that modern search engines and AI answer engines use to reward content that adds new information to a topic, not just covering it comprehensively… again. It traces to a 2018 Google patent that most articles misinterpret.
- There are two mechanically different paths to AI citation. The training-data path, which can be slow: your content enters a model’s weights when that model is trained (6 to 18 months between major releases) and stays encoded for the lifetime of that release. It is not permanent. The next model is a separate training run with a separate corpus, so re-inclusion is never automatic. The RAG path is fast and refreshable: Google AI Overviews, Google AI Mode, ChatGPT search, Perplexity, Claude search, and Copilot Search in Bing retrieve fresh content at query time and cite it within hours. They decompose each query into multiple sub-queries (a process called query fan-out) and retrieve them separately, which is why passage-level structure and FAQ-style sections matter. The current model’s weights are frozen, but the model can still see new content via RAG at runtime. Optimization moves differ for each path.
- Information Gain Density is the count of distinct, original, attributable insights in a piece, measured against the saturation of competing content. The 5-to-7 Rule says most competitive topics need 5 to 7 to credibly compete. Full framework in the dedicated Information Gain Density deep-dive.
- Information Gain Score (IGS) is the mathematical measure: 1 minus the maximum cosine similarity between your content’s vector embedding and the embeddings of the top-ranking competitors. A score above 0.5 is meaningfully different. Full operational walkthrough (embedding model choice, calibration grid, edge cases, code) in the dedicated Information Gain Score deep-dive.
- Vector shift is the geometric framing of what IGS measures: the motion of your document’s embedding away from the SERP median centroid into less-occupied vector space. Earned shifts (from new substance) compound; gamed shifts (from synonym swaps) decay. The earned-versus-gamed distinction is in the dedicated Vector Shift deep-dive.
- The 12 Information Gain Techniques are the comprehensive catalog of how to produce net new insight in any content piece. Most articles use one or two by accident. Winners use four to six deliberately.
- The single highest-leverage technique is a direct subject matter expert quote. Searchbloom has measured a 400% lift on average from this one move.
- Information Gain Density flows through all five pillars of the MERIT Framework. Evidence is where you author it most directly. Mentions delivers it through third-party content you didn’t author. Relevance elevates it through structural change. Inclusion makes it discoverable. Transformation measures and compounds it over time.

What the Google “Information Gain” Patent Actually Says
The patent everyone references is US Patent 11,354,342 B2, “Contextual Estimation of Link Information Gain,” filed by Victor Carbune and Pedro Gonnet at Google on October 18, 2018, and granted on June 7, 2022.
The abstract describes a method for determining a score “indicative of additional information that is included in the document beyond information contained in documents that were previously viewed by the user.”
Read that twice. The patent describes session-level personalization. It scores how much new information a document contains relative to documents the individual user has already seen in their session. It does not describe a global ranking factor that rewards content for being novel across the entire web.
This is the single most important thing most articles on information gain get wrong. They treat the patent as proof that Google globally rewards “different” content. The patent itself describes something narrower: filtering redundancy from one user’s session. The broader idea is still useful as a content quality framework. And while it may not be a confirmed ranking signal in Google’s documentation, my experience running these techniques across many SEO engagements makes me confident it functions as one in practice.
What the 2024 to 2026 Data Actually Shows
Independent research over the last two years gives a clearer picture of what AI search engines actually reward. Five findings matter most.
1. Original Data Drives Citations Measurably
The strongest peer-reviewed evidence comes from a Princeton research paper titled “GEO: Generative Engine Optimization” (Aggarwal et al., KDD 2024). The study tested which content modifications lift visibility in generative search engines and found three top-performing methods:
- Adding quotations: +42.6% lift in position-adjusted word count (the strongest single method tested).
- Adding statistics: +33% lift in position-adjusted word count.
- Citing sources: +28% lift in position-adjusted word count.
- The authors report a combined relative improvement of 30 to 40% on position-adjusted word count and 15 to 30% on subjective impression across the top-performing methods.
2. AI Overviews Cite More Than “Five Sources”
Surfer SEO’s 2025 AI Citation Report analyzed 36 million AI Overviews and 46 million citations between March and August 2025. Citation count scales with answer length: short AIOs cite about 5 sources, long AIOs cite up to 28, and the average across all queries is roughly 10 links from about 4 unique domains.
3. Conventional Rank Is Still the Largest Single Source of AI Citations
Ahrefs has now run this analysis twice. Their July 2025 study of 1.9 million citations found that 76% of AIO citations came from pages already ranking in Google’s top-10 organic results. The March 2026 republish, across 4 million citations from 863,000 SERPs, put that number at 38%. The drop is meaningful, but the directional read is the same: conventional rank is still the largest single source of AI citations, and the rest are increasingly coming from pages that rank for the sub-queries AI Overviews fan out to (which is exactly the behavior described in the query fan-out section below). The “SEO is dead” narrative does not survive either dataset. If you cannot rank conventionally for either your head term or its fan-out variants, you will not get cited at scale.
4. Retrievability Beats Pure Novelty
Ahrefs published an analysis of 1.4 million ChatGPT prompts in early 2025. The strongest signal of citation was title-query semantic similarity at 0.656 cosine for cited URLs versus 0.484 for non-cited URLs. ChatGPT cites pages whose titles match the user’s query (or, more precisely, the fan-out sub-queries it generates from that query). Information gain alone is not a winning strategy. Retrievability comes first; differentiation determines which retrievable page gets cited.
5. AI-Assisted Content Dominates AI Citations
Per Ahrefs (July 2025), 87.8% of AIO-cited pages were AI/human mixes, while only 8.6% were purely human-written. The narrative that Google AI Overviews preferentially reward “human originality” does not hold up empirically. AI-assisted content, structured well and grounded in original data, is winning. Hard.
6. AI Engines Show a Systematic Bias Toward Earned Media
A 2025 follow-up GEO study (“Generative Engine Optimization: How to Dominate AI Search”) ran controlled experiments across multiple verticals, languages, and query paraphrases. The headline finding: AI search engines exhibit “a systematic and overwhelming bias toward Earned media (third-party, authoritative sources) over Brand-owned and Social content.” This is a sharper version of the Reddit and UGC pattern: citation share at scale increasingly requires winning on third-party domains you don’t author (earned media, Reddit, YouTube, LinkedIn), not just on owned pages. This is the Mentions pillar of MERIT in practice and the reason owned-content optimization alone tops out.
7. Content Placement on the Page Is Now a Citation Factor
Two independent primary studies in 2026 found that AI search disproportionately cites content from the top of a page. CXL’s March 2026 study (Tarek Reslan) mapped 100 AI Overview citations to where within each source page the cited snippet appeared. 55% came from the top 30% of the page, 24% from the middle (30-60%), and only 21% from the bottom 40%. The 10-20% zone alone produced more citations than any other decile. Kevin Indig’s parallel analysis of 1.2 million search results and 18,012 verified ChatGPT citations found 44.2% of ChatGPT citations come from the first 30% of a document. Indig describes the curve as a “ski ramp”: a steep cliff after the first third, then a long, slow tail. In his measurement, burying a definition or finding past the 30% mark reduces retrieval probability by roughly 2.5x compared to the introduction. The operational implication: front-load your core claim, definition, or stat in the first 150 to 200 words of any priority page. The exception worth noting is FAQ sections, which earn citations from deep-page positions because each question-answer pair is structurally self-contained and answer-first. (This is one reason this article carries 18 FAQ entries instead of 5.)
How AI Actually Sees Your Content: The Two Paths
Most articles on AI search talk about “getting cited” without explaining how citation actually happens. There are two completely separate mechanisms with different physics and different optimization moves. Understanding the difference is foundational to everything else in this article.
| Path 1: Training Data | Path 2: RAG (Retrieval) | |
|---|---|---|
| Speed | 6 to 18 months between major model releases | Hours to days from publication |
| Mechanism | Embedded into model weights at training time | Retrieved fresh at query time, fed as context |
| Permanence | Frozen for the lifetime of that model release | Re-evaluated every query |
| Wins via | CCBot, GPTBot, ClaudeBot, and Google-Extended access; named-concept repetition; third-party authoritative mirroring | Top-10 organic ranking; title-query semantic match (0.656 cosine); passage-level structure; IGS differentiation |
| Backends | Common Crawl, GitHub, Wikipedia, YouTube, Reddit (licensed), Wayback Machine | Google index (AIO, AI Mode, Gemini); Bing (ChatGPT, Copilot Search); Brave (Claude); PerplexityBot index |
The current model’s weights are frozen, but RAG can show it new content at runtime
When Claude Opus 4.7, GPT-5, or Gemini 2.5 were trained, every embedding in the model’s weights was set. Inference does not update those embeddings. There is no online learning, no memory across conversations, and no automatic ingestion of new content into model weights. The weights are frozen.
Memory features (ChatGPT Projects Memory, Claude Projects Memory, custom GPTs, Gemini Gems) and uploaded project files are not exceptions. They work by injecting text into the model’s context window at inference time, mechanically similar to RAG. Think of it as a pre-prompt for the prompt you’re about to do. The model reads them at the start of each conversation, but the underlying weights stay frozen. Your “memory” with a model is text that the system re-reads on every turn, not learning baked into the model itself.
However, the model can still see and synthesize new content at runtime via retrieval-augmented generation. A separate retrieval system pulls fresh content from a search index, embeds it on the fly with a separate embedding model, and feeds it to the LLM as context for a single query. The model’s weights stay frozen, but the model’s outputs incorporate the retrieved content. This distinction matters because your content reaches AI systems through two distinct paths.
Path 1: The training-data path (slow, baked into a model release)
When Anthropic, OpenAI, Google, and others train their next model, they ingest fresh training data: new web crawl, new documents, new datasets. Your article, if it is in places LLMs crawl, becomes part of the next model’s embedding space. Once embedded, it is part of what that model knows for the lifetime of that release, even when no retrieval is happening. This is not the same as “permanent”: future models trained on different corpora may filter your content differently, deprioritize older content, or omit it entirely if it has been removed from the web by then.
Timeline: typically 6 to 18 months between major training runs. Content published this month enters the next major model release.
What wins on this path:
- Allowing the training crawlers in robots.txt: CCBot (Common Crawl), GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Gemini training), and PerplexityBot. These are separate from Googlebot and Bingbot.
- Being crawled before the model’s training cutoff. Common Crawl publishes monthly snapshots; if your content is not in a snapshot that predates the cutoff, it cannot be in that model’s weights.
- Producing content with named concepts that get repeated and cited by other publishers (frameworks, formulas, terminology like “Information Gain Density” or “the 5-to-7 Rule”). Repetition across sources is what cements an idea into model weights.
- Being mirrored on third-party authoritative domains that are heavily weighted in training corpora: Reddit, GitHub, Wikipedia, and YouTube transcripts.
- Content that becomes durable reference material rather than time-sensitive news.
Path 2: The retrieval-augmented generation (RAG) path (fast, refreshable)
Google AI Overviews, ChatGPT search, Perplexity, Claude search, and Copilot Search in Bing all work via retrieval-augmented generation. They do not rely on the model’s frozen weights for current information. They retrieve fresh web content at query time, embed it on the fly using a separate embedding model (text-embedding-3-large, voyage-3, BGE-M3, or similar), find the closest matches to the user’s query in a vector index, and feed the top matches to the LLM as context. The LLM then synthesizes an answer and cites the sources it pulled.
Timeline: hours to days between publication and citation eligibility, assuming the content gets crawled and indexed.
I’ve personally used the IndexNow and Google Indexing APIs and seen SERP changes within minutes. Note: Google’s Indexing API is officially limited to JobPosting and BroadcastEvent content. Using it for general URLs isn’t sanctioned, even though it works.
~ Cody C. Jensen, CEO, Searchbloom
What wins on this path:
- Conventional ranking signals (top-10 organic rankings, schema, indexability, retrievability)
- Title-query semantic match (the 0.656 cosine finding from Ahrefs)
- Passage-level structure (each section can be retrieved as a chunk)
- IGS-style differentiation from competing pages already in the index
- Indexation in the right backends for the AI products you care about (see below)
Where each AI product retrieves from
Different AI products use different search backends and data sources for the RAG path. As of mid-2026:
- Google AI Overviews and AI Mode retrieve from Google’s search index, which now includes licensed real-time Reddit data via Google’s $60M/year deal.
- Gemini (Google’s standalone chatbot) grounds web-search queries via Google’s search index, the same retrieval backend that powers AI Overviews and AI Mode.
- ChatGPT search retrieves primarily from Bing (via OpenAI’s Microsoft partnership), supplemented by OpenAI’s own crawler (OAI-SearchBot) and licensed datasets.
- Perplexity uses its own crawler (PerplexityBot) and index, with heavy citation of Reddit and YouTube.
- Claude search uses the Brave Search API for web retrieval, confirmed via Anthropic’s subprocessor disclosure.
- Copilot Search in Bing (formerly Bing Generative Search) is Bing’s equivalent of Google AI Overviews and retrieves from Bing’s index directly.
Where each AI product trains from (and why it is not the same as where it retrieves from)
Common Crawl is the foundational training corpus for nearly every major LLM that is not Google. The nonprofit has been crawling the web since 2008 via its bot, CCBot, and now contains over 240 billion pages across more than 100 monthly snapshots. GPT-3 drew 82% of its training tokens from Common Crawl. Anthropic and OpenAI have each donated $250,000 to fund the project. The major filtered derivatives, all built on top of Common Crawl, include C4 (Google’s clean version, used to train T5), RefinedWeb (used for Falcon), and FineWeb (HuggingFace’s curated version, used for many open-weight models).
Beyond Common Crawl, the training corpus for a frontier model also includes:
- Licensed publisher data: Reddit ($60M/year to Google, roughly $70M/year to OpenAI), plus News Corp, Associated Press, Financial Times, Axel Springer, and Condé Nast deals with OpenAI and others.
- GitHub for code (universal across code-capable models, often via The Stack dataset).
- Wikipedia dumps (universal across all major LLMs).
- YouTube transcripts (especially relevant for Google’s Gemini and for any model trained on auto-captioned web video).
- The Internet Archive’s Wayback Machine ingests Common Crawl mirrors among other sources and holds 835 billion+ pages back to 1996. No major commercial AI product uses archive.org as a primary retrieval backend at query time, but Wayback content has been documented in training corpora; web.archive.org ranked as the 187th most-present domain in Google’s C4 dataset, the same corpus used to train T5 and Llama.
- Each model trainer’s own targeted crawls: GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Google’s separate user-agent for Gemini training, distinct from Googlebot), PerplexityBot (Perplexity), Bytespider (ByteDance), and others.
The crawler distinction most SEO operators miss. Googlebot is what puts you in Google’s search results, which feeds Path 2 (RAG). CCBot, GPTBot, ClaudeBot, and Google-Extended are what put you into LLM training data, which feeds Path 1. They are different bots with different user-agents, different crawl frequencies, and different robots.txt directives. Blocking Googlebot kills your conventional SEO. Blocking CCBot, GPTBot, ClaudeBot, or Google-Extended quietly kills your Path 1 visibility while leaving your Google rankings intact. Many sites have inadvertently blocked one set without realizing the other set exists.
If you want to be explicit about what you allow, your robots.txt should call out the training crawlers by name, though it is unnecessary in my personal experience:
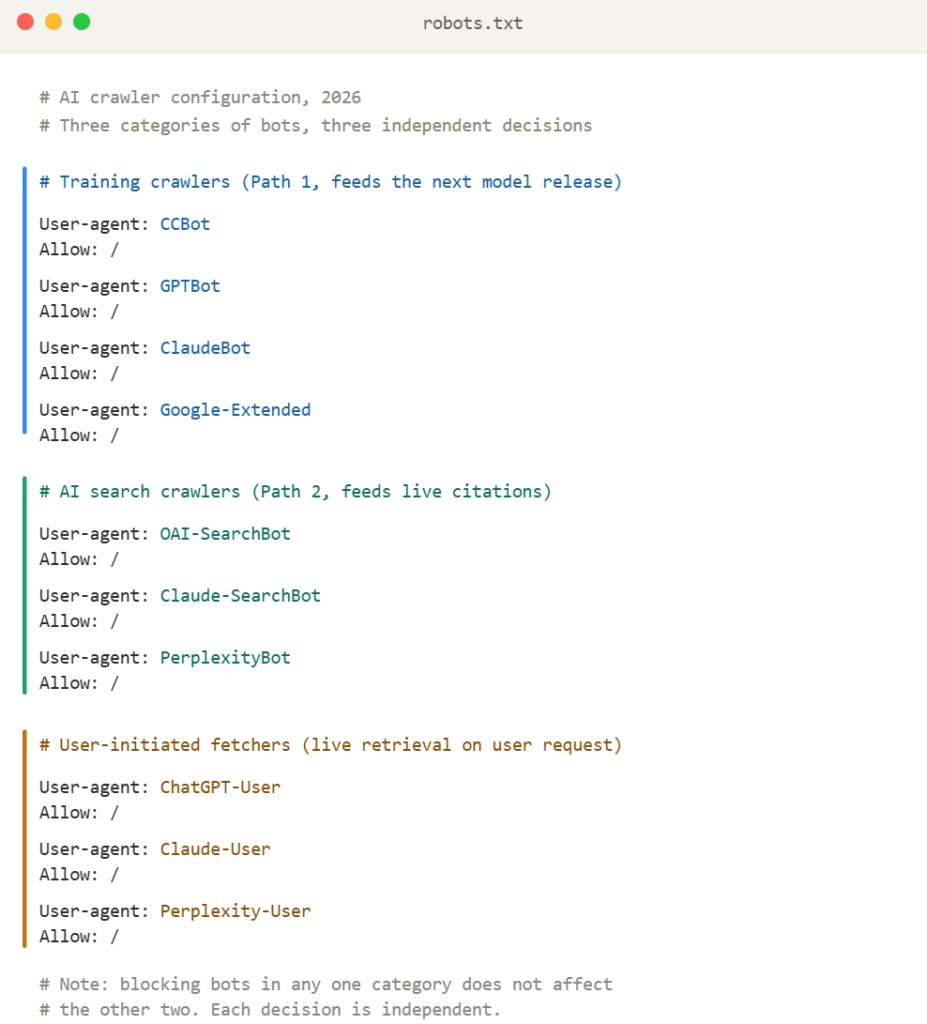
The implication for retrieval (Path 2): ranking in Google does not automatically mean ranking in Bing, and vice versa. If you want citations across all major AI products, you need to be indexed in both Google and Bing, and discoverable to Brave’s index for Claude. For Perplexity specifically, Reddit and YouTube presence matter as separate citation channels. Independent research found Reddit, YouTube, and LinkedIn are the three most-cited sources across AI engines. (Peec AI)
Query fan-out: AI products decompose your query before retrieval
Most current AI search products do not run a single retrieval against your literal query. They decompose the query into sub-queries (a process called query fan-out) and retrieve documents for each sub-query separately. Then they synthesize across all the retrieved results.
For example, a query like “compare information gain density vs topical authority” might fan out to:
- “what is information gain density”
- “what is topical authority”
- “differences between information gain and topical authority”
- “information gain density definition”
- “topical authority SEO”
Your content might be retrieved for some sub-queries but not others. Different parts of your content might be selected for different sub-queries. Three implications follow:
- Passage-level structure compounds in value. Each section of your content needs to be a complete answer to a discrete sub-question, because each sub-query runs its own retrieval against the index.
- Owning multiple sub-questions outright beats competing on one head term. The 5-to-7 Rule’s emphasis on owning 2 to 3 sub-questions is calibrated to query fan-out behavior rather than single-query retrieval.
- FAQ schema becomes high-leverage. Each FAQ entry is structurally a sub-query answer, which is exactly the format the fan-out process is looking for. This is why the FAQ section in this article has 18 entries instead of 5.
Why the IGS formula is actually predicting RAG behavior
The Information Gain Score formula (cosine similarity to the top-ranking competitors, subtracted from 1) is not abstract math. It is a direct prediction of what RAG systems do at query time. When ChatGPT search receives a query, it embeds the query, embeds candidate documents, computes cosine similarities, and picks the most relevant and differentiated documents to feed to the LLM. The IGS calculation predicts whether your content survives that selection step.
This is why IGS works for both paths but matters most for Path 2. For Path 1 (training data), the question is whether your embedding adds something new to the next model’s embedding space. For Path 2 (RAG), the question is whether your embedding wins the cosine-similarity contest right now.
The strategic implication
Most content marketers conflate the two paths and optimize for neither well. The honest framework is:
- For Path 1 (next training): publish in places the major training corpora actually crawl (Common Crawl, indexed web, Reddit, GitHub, YouTube), build durable reference material with named concepts that get repeated by other publishers, prioritize content that becomes baseline knowledge the next model release just knows.
- For Path 2 (RAG today): win at conventional SEO, structure content for passage-level retrieval, hit the IGS threshold against current top-10 competitors.
The 12 Information Gain Techniques feed both paths. But the optimization moves differ. Most articles ignore this distinction and end up half-optimizing for both. Get clear on which path is your priority and the choices simplify.
Information Gain Density: A Framework
Most articles tell you to “add information gain” without telling you how much you actually need. So we built a framework for it. Information Gain Density (IGD) is the count of distinct, original, attributable insights in a piece of content, measured against the saturation level of competing content for the same query. The empirical benchmark is the 5-to-7 Rule: most competitive topics in 2026 require five to seven distinct insights to credibly compete in AI search. Across roughly four hundred priority pages we have audited, absorbed pages typically carry zero to one original insights; cited pages carry five or more.
For an insight to count toward density, it must:
- Be specific enough to be quoted (a stat, a named failure mode, a contrarian claim, a proprietary data point, a coined term)
- Be attributable to you (your data, your experience, your framework)
- Fail the “could ChatGPT have written this paragraph from existing sources” test
The per-section audit procedure, the failure modes, the origin story, and the worked examples behind each criterion are in the dedicated Information Gain Density deep-dive.
The Information Gain Score: How to Measure It
Information Gain Density is the framework. The Information Gain Score is the math.
The formula:
IGS = 1 - max(cos_sim(E(d), E(ci)))Where:
E(d) = the vector embedding of your document
E(ci) = the vector embedding of competing document i in the top N pages already ranking for your target query
cos_sim = cosine similarity, the standard math for comparing embeddings
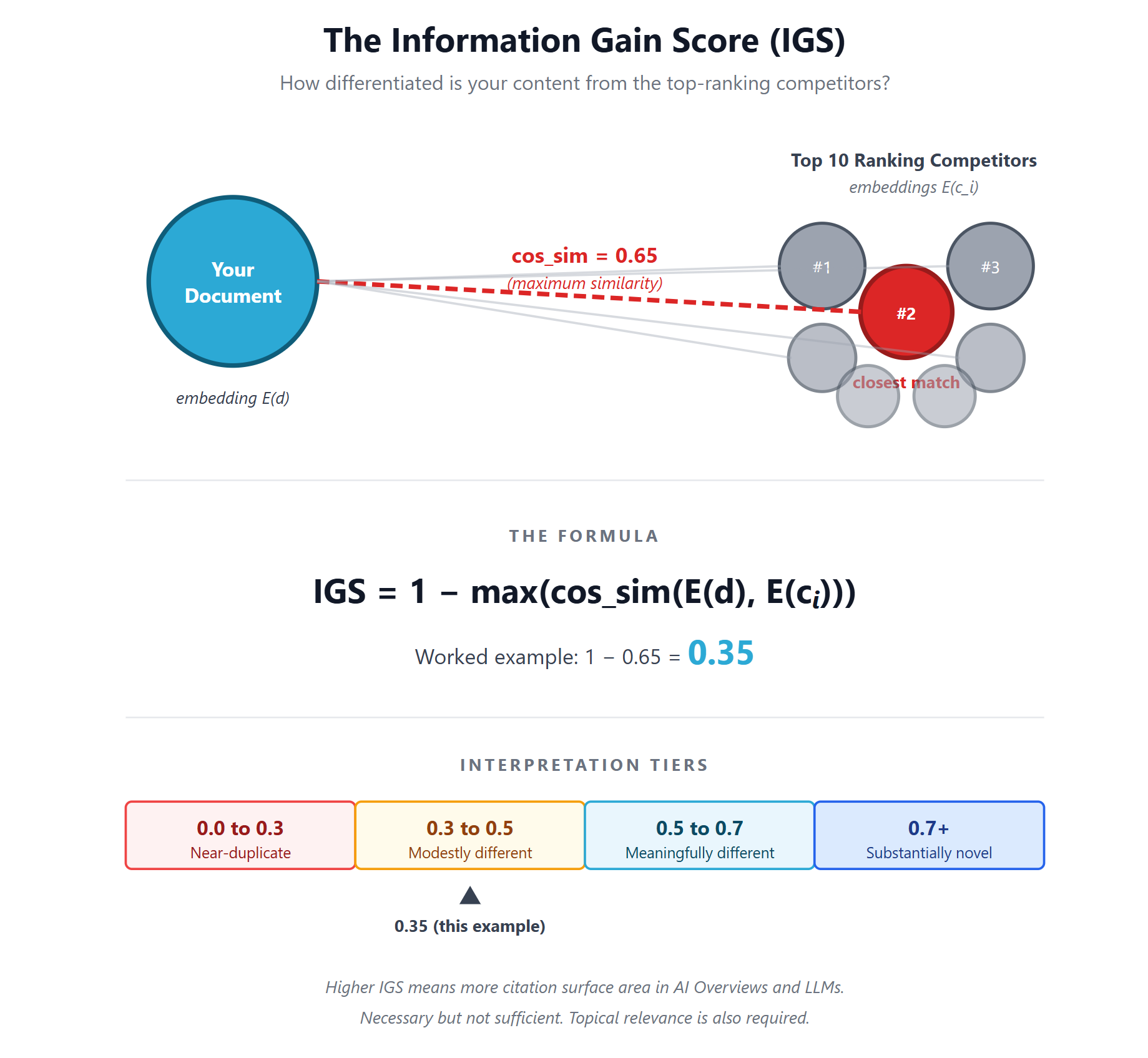
In plain English. Take the top 10 pages already ranking for your target query. Convert each one to its vector embedding (a sequence of numbers, typically 768 to 3,072 dimensions, that represents the meaning of the content the way an AI engine would interpret it). Convert your own page the same way. Find the closest match, the existing page yours is most similar to. Subtract that similarity from 1. The number you are left with is your Information Gain Score.
A score of 0 means your content is essentially a duplicate of an existing top-ranked page. A score close to 1 means you have written something substantially different from anything ranking today.
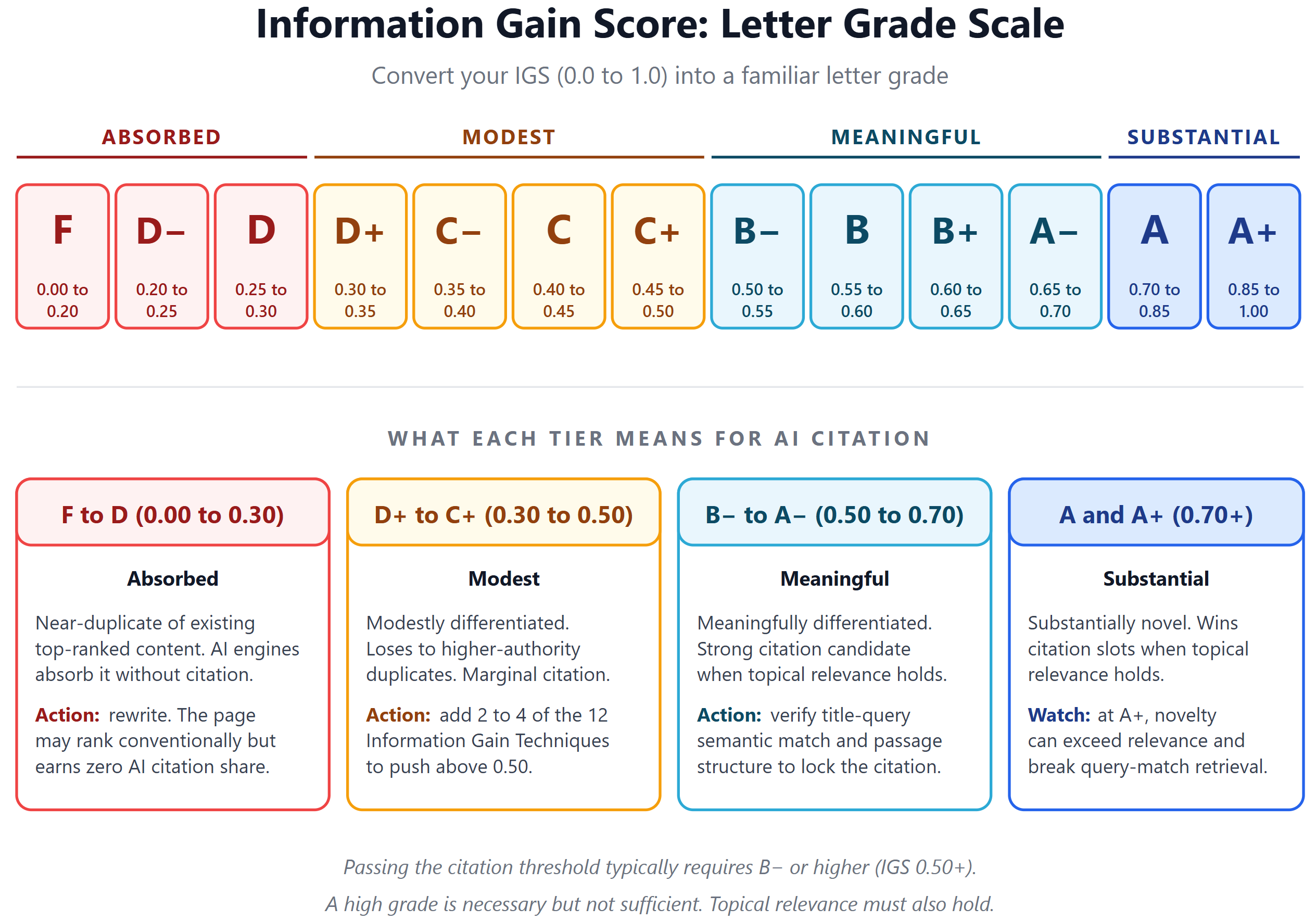
Interpretation Tiers
The IGS scale maps cleanly onto a familiar letter grade. F to D is absorbed, D+ to C+ is modest, B- to A- is meaningful (the citation threshold), and A to A+ is substantial. The granular 13-grade breakdown is in the diagram below the table.
| IGS Range | Letter Grade | Interpretation | Likely Outcome |
|---|---|---|---|
| 0.0 to 0.3 | F to D | Near-duplicate of existing top-ranked content (Absorbed) | AI engines absorb without citation. The page may rank conventionally but earns no AI citation share. |
| 0.3 to 0.5 | D+ to C+ | Modestly differentiated | Loses to higher-authority duplicates. Marginal citation opportunity. |
| 0.5 to 0.7 | B- to A- | Meaningfully differentiated | Strong citation candidate when topical relevance holds. |
| 0.7+ | A and A+ | Substantially novel | Wins citation slots when topical relevance holds. Risk of becoming so different that relevance breaks. |
The Honest Caveat: IGS Is Necessary But Not Sufficient
A high IGS does not guarantee citation; you still need topical relevance. Ahrefs’ April 2026 analysis of 1.4 million ChatGPT prompts found title-query semantic similarity at 0.656 cosine was the single strongest predictor of ChatGPT citation, and high IGS on an irrelevant page is a moat around an empty room.
Why This Matters Operationally
Most agencies have no way to tell you whether a piece of content is differentiated until after they publish and watch the rankings. IGS lets you measure it before you publish. We use this internally at Searchbloom and run an IGS analysis against the target query for each priority page. The full operational walkthrough (embedding model selection, the calibration grid, edge cases, the spreadsheet template) lives in the dedicated Information Gain Score deep-dive. The same motion has also been called a “vector shift” away from the SERP median (a framing introduced by Krish Srinivasan at Search Engine Zine in March 2026). IGS is the math; vector shift is the geometric image. Our Vector Shift deep-dive covers the earned-versus-gamed distinction and the direction question (topical shift versus off-topic drift) in detail.
The Single Highest-Leverage Move: Direct Subject Matter Expert Quotes
If you only do one thing this year, do this: add a direct quote from a subject matter expert, in their own words, to every priority page.
I will quote myself on this because we have measured it directly across some of our partner-clients.
“A direct quote from the subject matter expert, in their own words, produces an average 400% lift across AI Mode, AI Overviews, Copilot Search in Bing, LLM visibility, and organic Google rankings.”
~ Cody C. Jensen, CEO, Searchbloom
Methodology: averaged across 25 Searchbloom SEO engagements over a rolling 90-day window, comparing each priority page before and after a subject matter expert quote was added. “Visibility” is a composite of impressions (Google Search Console and Bing Webmaster Tools) plus citations and mentions tracked via Peec AI across AI Overviews, AI Mode, Copilot Search in Bing, ChatGPT, Claude, Gemini, and Perplexity. Citation and mention counts are used in place of impressions where the platform does not expose impression-level data.
Three converging reasons explain why this works.
1. Original Quotes Push the Information Gain Score Up
A direct, in-someone’s-voice quote almost always pushes IGS up by 0.1 to 0.3 in our internal testing, because no other page has that exact sentence in that exact voice. The quote itself is a piece of content with no embedding twin in the existing corpus.
2. Quotes Are Passage-Level Retrievable
AI search retrieves chunks, not whole pages. A standalone quote with a clear attribution line is one of the most extraction-friendly formats possible. The retrieval layer can pull it out with no surrounding context required, which is exactly what passage-level optimization (sometimes called Relevance Engineering, a term coined by Michael King at iPullRank) calls for.
3. Quotes Activate the Experience Pillar of E-E-A-T
Google and AI engines both reward signals of first-hand experience. A real quote from a real practitioner is the single strongest signal of that pillar. Generic content cannot fake it. Synthesized content cannot reproduce it.
The friction is not technical. It is operational. Most agencies skip the SME quote because they do not want to schedule a 15-minute call with the partner. Schedule the call. Do the work. The 400% lift is real.
Where Information Gain Lives in MERIT
We use the MERIT Framework at Searchbloom to organize AI search optimization work across thirteen strategies and five pillars. Information Gain Density flows through all five. Evidence is where you author it most directly; the other four pillars contribute distinct forms, as we’ll show.
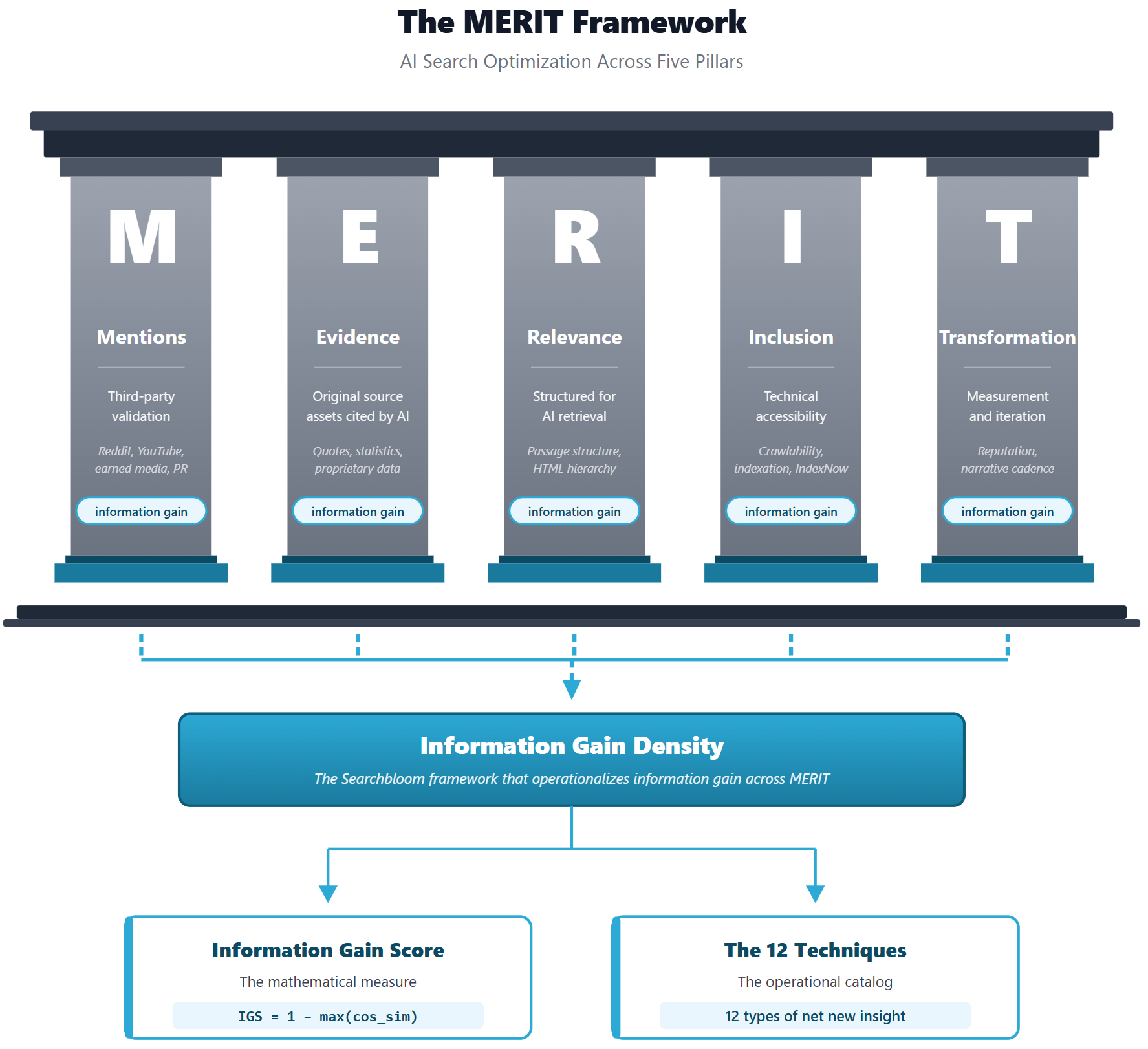
- M is for Mentions. Third-party validation through review platforms, community engagement, and earned media. Reddit, YouTube, LinkedIn, podcasts, and PR live here.
- E is for Evidence. Original source assets that AI engines cite. This is where you author Information Gain Density most directly: your quotes, statistics, proprietary research, named frameworks, original data.
- R is for Relevance. Content structured for AI retrieval. Passage-level architecture, schema markup, semantic alignment with target queries.
- I is for Inclusion. Technical accessibility for AI crawlers. Crawlability, indexation, rendering, IndexNow.
- T is for Transformation. Measurement, narrative consistency, reputation alignment, and organizational evolution.
Information Gain Density isn’t confined to Evidence. Each pillar contributes a distinct form. Mentions delivers IGD you didn’t author: a new third-party review on G2 or Trustpilot adds visibility-shaping content into the corpus AI engines retrieve from when answering prompts like “should I use [your company].” Relevance elevates IGD through structural change: the same underlying facts, restructured into discrete HTML sections with clear heading hierarchy and self-contained passages, produce a higher IGS because the embedding shifts (LLMs parse HTML and markdown directly, so structural changes to visible content move the embedding; schema markup does not, because schema is upstream of the LLM, helping the search indexes the RAG layer retrieves from, not the LLM itself). Inclusion makes IGD discoverable: gain that isn’t crawled or indexed is invisible to AI engines, and IndexNow accelerates the path from publication to retrieval. Transformation measures and compounds IGD over time: without measurement infrastructure you don’t know which efforts are working, and narrative consistency makes named concepts compound across content. Evidence is where you author IGD most directly. The other four are where it originates outside your direct authoring, multiplies through structure, manifests through reach, and compounds through measurement.
Optimizing one pillar in isolation falls flat. Evidence without Inclusion is gain that isn’t reachable. Inclusion without Evidence is empty pages indexed. Mentions without owned substance is reputation pointing at nothing. Relevance without Evidence is well-structured nothing. The full MERIT framework addresses all five together because Information Gain Density compounds across pillars: Evidence creates substance, Mentions amplifies it through third-party validation, Relevance makes it retrievable, Inclusion makes it discoverable, and Transformation measures and refines it over time.
The Four Strategies Most Discussed (and What They Miss)
The popular framing of information gain centers on four strategies for adding novel value to content:
- Original research and proprietary data. Customer surveys, product usage statistics, expert interviews, first-hand experience.
- Build on or challenge predecessors. Skip the 101. Write the 102. Pick one concept that other articles mention briefly and go deeper than anyone else.
- Risky framings and contrarian angles. The safest content is the most synthesizable. Strong stances and updates to outdated consensus stand out.
- Specific cohorts. Generic advice for “marketers” gets absorbed. Advice for “Series B SaaS marketing leads with $500K to $2M ARR” does not.
These four still hold up. They are necessary but no longer sufficient. Three additions are now load-bearing.
Reddit and UGC Are the Largest AI Citation Source
Reddit citations in AI Overviews grew 450% between March and June 2025. Reddit overtook Wikipedia as the #1 AI citation source across most engines in 2025. Perplexity cites Reddit roughly 24% of the time (per Search Engine Land’s analysis of 30 million AI citation sources). If you are not building presence on Reddit, YouTube, or LinkedIn, you are giving away the largest single channel of AI citation real estate. This is the Mentions pillar of MERIT in practice.
Passage-Level Structure
AI search retrieves chunks, not full pages. The retrieval layer extracts passages of a few sentences to a few hundred words, then the language model synthesizes those passages into an answer. Each section of your content needs to stand alone as a citable answer. If a passage requires three preceding paragraphs of context to make sense, it will not get cited. Write so that any heading-bounded section can be lifted out of context and still answer a discrete question. This is exactly why this post is structured the way it is.
Schema Markup as a GEO Tactic
Aleyda Solis’s 2025 survey of 200 SEOs identified structured data as one of the most consistently helpful Generative Engine Optimization tactics. FAQ schema, Article schema, HowTo schema, and Product schema each give AI search engines explicit signals about what your content answers. The FAQ schema markup in this post is operationalization, not decoration.
Note: LLMs do not directly parse schema.org markup. Schema is still important, but its role is upstream of the LLM: search engines parse it to build indices and knowledge graphs, and the RAG path that AI products use retrieves from those indices.
The 12 Information Gain Techniques
Information gain shows up in twelve distinct, recognizable forms. Most articles use one or two by accident. The pieces that win in AI search use four to six deliberately. We call these the 12 Information Gain Techniques. They are the operational catalog of how to author Information Gain Density most directly on a priority page, the Evidence-pillar contribution to IGD. Use them as a checklist on every priority page.

Technique 1: Proprietary Aggregate Data
Metrics drawn from your operations or book of business that no competitor has access to. Example: “Across Searchbloom’s partner-clients, adding a direct subject matter expert quote produces an average 400% lift across AI Mode, AI Overviews, Copilot Search in Bing, LLM visibility, and organic Google rankings.” AI engines cannot synthesize numbers that only exist in your CRM. This is the strongest technique for service businesses, agencies, and SaaS companies sitting on operational data they have never published.
Technique 2: First-Hand Case Studies
A specific engagement examined with named details, real numbers, and a documented before-and-after. The detail level of one case beats the abstraction of ten generic case study summaries because each named fact (the industry, the size, the timeline, the specific strategy, the specific result) becomes its own citation hook. AI Overviews retrieve at the passage level, so a case study with a dozen specific facts produces a dozen retrievable passages.
Technique 3: Subject Matter Expert Quotes
Direct, in-voice statements from a practitioner about a topic, attributed clearly. A unique voice produces a unique embedding, quotes are passage-level retrievable with no surrounding context required, and they activate the Experience pillar of E-E-A-T. This is the highest-leverage single technique, with a 400% measured lift across Searchbloom’s partner-clients. Most agencies skip it because it requires a real conversation with the practitioner instead of a content template.
Technique 4: Failure Documentation
Published accounts of what did not work, why, and what was learned, with the same rigor as success cases. Survivorship bias means the entire web is biased toward “here is the playbook that worked.” Failure documentation is structurally rare and gets cited at higher rates because it answers questions other content avoids. Most marketing teams have a folder of campaigns nobody talks about. Publish them.
Technique 5: Named Failure Modes With Cohort Specificity
A specific, named mistake pattern observed in a specific, named cohort, described with diagnostic precision. “DIY plumbing fails” gets absorbed by AI synthesis. “PEX-to-galvanized transitions fail in 1920s LA bungalows because there is no dielectric union, leading to pinhole leaks within 18 months and roughly $4,000 in remediation” gets cited. The difference is diagnostic precision applied to a specific cohort. A failure mode is the named mechanism that causes something to break. A cohort is the specific population it breaks for. Generic advice describes neither. Cited content names both, then quantifies the consequence. The principle holds in any industry. Another example: “Site migrations on WordPress that change permalink structure without 301 maps lose roughly 30 percent of historical link equity within 90 days, and recover only partially even with retroactive redirects.” Same anatomy: named mechanism, named cohort, quantified consequence.
Technique 6: Pricing and Economic Transparency
Publishing real numbers, prices, ranges, ROI distributions, and unit economics that competitors structurally avoid disclosing. Most service businesses bury their economics. Publishing them is uncopyable because everyone else is structurally afraid to do so. Concrete example: instead of “pricing varies by scope,” publish the actual ranges with what drives them. “A typical mid-market SEO retainer ranges from $8,500 to $24,000 per month. The floor is set by websites with fewer than 50 priority pages in a single market. The ceiling is set by enterprise websites with multi-domain or multi-lingual footprints, international hreflang complexity, or weekly content cadence. The median engagement is around $14,000 per month and runs 12 to 18 months before scope renegotiation.” That paragraph is uncopyable not because the numbers are secret, but because most agencies are operationally unwilling to anchor themselves to a published range.
Technique 7: Process and Timeline Transparency
Documenting what an engagement, project, or implementation actually looks like week by week, with real dependencies and decision points. Most agencies advertise outcomes but never publish process. The actual cadence and dependencies are what operators want to know. Example: “Month one of an SEO retainer typically covers technical audit, priority page selection, content gap analysis, and SME interview scheduling. Months two and three are where the work actually publishes, content production, on-page optimization, and the first round of measurement infrastructure. Month four is the first honest read on whether the strategy is working, and where most engagements either earn renewal or surface the misalignment that kills them. Months five through twelve compound on whatever worked in the first hundred days. Most agencies skip the month-four honesty conversation because it is uncomfortable. That avoidance is why average engagement length in the industry is shorter than it should be. The misalignments that kill engagements at month four cluster around three patterns: partner SMEs who never made time for interviews, priority pages chosen by stakeholder politics rather than IGS analysis or with unrealistic expectations, and goals that conflated AI citation with conventional ranking. Naming the failure mode early in the engagement is the difference between a renewal and a churn.”
Technique 8: Operational Artifacts
Real, downloadable templates, scripts, checklists, queries, or configurations that you actually use in production. AI can describe a checklist generically. Only an operator can hand you the one their team uses with their partners on Monday morning. The artifact itself is the gain. Examples: the SQL query you run weekly to pull AIO citation deltas, the pre-publish checklist your editorial team works through before anything publishes, the Slack message template you send to a partner when a new AIO citation drops, the IGS calculation spreadsheet you score drafts against. Each one is a piece of operator knowledge made portable. Each one passes the “could ChatGPT have written this” test because the specific cells, the specific column headers, and the specific decision logic only exist because someone built them in response to a real problem.
The reason this technique compounds is that artifacts are the highest-trust form of content. A reader who downloads your IGS spreadsheet is not just citing your article; they are running your process. That artifact then sits in their workflow, gets shared with their team, and gets referenced every time the topic comes up internally. The citation surface area extends well beyond the original page. Most agencies hoard their templates because they feel like proprietary value. Publishing them is the move that signals you have enough proprietary value to give some away.
Technique 9: Decision Frameworks With Explicit Tradeoffs
Structured guidance on when to choose option A versus B versus C, with the actual criteria rather than the “it depends” handwave. Most content gives you the options. Few give you the decision criteria. Example: “Choose Surfer for content scoring when you have a high-volume content team producing 20+ pieces per month and you need consistent on-page optimization without manual review of each draft. Choose MarketMuse when you have an editorial-led brand where every piece is a deliberate publication and you need topic modeling depth more than throughput. Skip both when your priority pages are under 30 and you can do manual IGS analysis instead, because the tools price assumes a content velocity that small priority lists do not justify.” Decision frameworks pass a different test than informational content. A reader is not asking “what are my options,” they are asking “what should I actually do.” Content that names the criteria forces the writer to commit to a position, which is what makes the passage uncopyable. Generic comparison content can list features. Only an operator who has run all three paths can tell you which signal in your situation should override which other signal. Most decision frameworks online are written by people who have not actually used the options they are comparing, which is why they default to “it depends” and let the reader do the work. The leverage compounds when the framework names the failure mode for each option. Choosing Surfer when you actually have an editorial-led brand produces content that scores well and reads like a template. Choosing MarketMuse when you have high content velocity produces a bottleneck where every piece waits on topic modeling that the team does not have time to absorb. Naming what goes wrong with the wrong choice is what turns a comparison into a decision framework.
Technique 10: Verbatim Customer Language
The exact phrases customers, partners, or users use to describe their pain, their goals, or their workarounds, captured in their own words and not paraphrased. AI generates plausible-sounding customer voice. Real verbatim language is uncopyable until published, and once published it gets cited because it rings true. Example: a SaaS marketing page describing “advanced analytics dashboards for data-driven teams” is generic. A page that quotes a real partner saying “I stopped opening the dashboard because I could not figure out which of the seventeen metrics was the one my CMO actually asked about” is uncopyable. The first version was written by someone imagining what a customer might want. The second was written by someone who listened to a customer describe what they actually do. AI engines can reproduce the first sentence in their sleep. The second sentence has no embedding twin in the existing corpus because it only existed in one person’s head until someone published it. Pull from sales call transcripts, support tickets, post-purchase surveys, churn interviews, and onboarding feedback forms. The richest source is usually the conversation that happens right after a problem gets solved, because that is when customers articulate the workaround they had been using, the workaround they wished existed, and the gap between the two. Most of that language never makes it past a CRM note because the company treats it as feedback rather than content. Publishing it converts internal feedback into external information gain. The reason this technique compounds is that verbatim language carries credibility weight that synthesized language cannot. A reader who encounters real customer phrasing on a page recognizes the texture of actual experience, even if they cannot articulate why. AI engines pick up on the same signal, because the embedding of an authentic customer sentence sits in a different region of vector space than the embedding of marketing-team customer voice. Most companies sanitize their customer language before publishing it. The sanitization is what kills the citation potential. Publish the messy version.
Technique 11: Contrarian Framings and Strong Stances
Publicly stated positions that contradict consensus or call out widely-accepted wisdom as wrong, supported by reasoning and evidence. Safe content is the most synthesizable. Strong stances produce embeddings that do not twin with consensus articles. Example: this article’s position that the Google information gain patent does not say what the SEO community claims it says. The consensus framing treats the patent as proof that Google globally rewards novel content. Reading the patent shows it describes session-level personalization that filters redundancy for individual users. The contrarian position is not that information gain is unimportant; it is that the patent does not support the global-ranking-factor claim that has been repeated thousands of times. Stake the position. Defend it with primary sources. Contrarian framings produce embeddings that sit in unoccupied regions of vector space. When a thousand articles agree that X is true, their embeddings cluster tightly around a shared centroid, and any new article that repeats the consensus gets absorbed into the same cluster without meaningful differentiation. An article that argues X is wrong, or that X is true but for different reasons than the consensus claims, lands in a region where no other article currently sits. AI engines retrieve from sparse regions of vector space disproportionately because those regions are where novel information lives. The risk is the technique that distinguishes operators from contrarians-for-attention. A strong stance without primary-source support reads as opinion content and gets weighted accordingly by AI engines, which increasingly favor cited authority over rhetorical force. The pattern that wins is contrarian-on-the-claim, conventional-on-the-evidence: name the consensus position, link to where it appears, link to the primary source the consensus is allegedly based on, and show specifically where the two diverge. Most contrarian content skips the second link because tracking down the original source is real work. That work is exactly what makes the contrarian position uncopyable.
Technique 12: Cross-Domain Synthesis
Combining expertise from two fields that rarely meet, in a way that produces insight neither field alone could have produced. AI can fake the surface synthesis but not the field-tested judgment about what crosses cleanly versus what does not. Example: applying behavioral economics framings to plumbing service pricing produces insights neither field alone would surface. A plumber pricing emergency calls at $385 versus $400 changes conversion rates by more than the $15 difference would predict, because $385 sits below the price-anchor threshold most homeowners use to decide whether to call a second plumber. The behavioral economist understands the anchor mechanism but has never priced an emergency call. The plumber has priced ten thousand calls but has never named the mechanism. The synthesis only happens when someone has worked both sides long enough to know which behavioral framings transfer to physical service pricing and which ones do not.
The reason AI struggles to fake this technique is that surface synthesis is easy and field-tested synthesis is not. An LLM can produce a paragraph titled “applying behavioral economics to plumbing” that sounds plausible. The paragraph will list anchoring, loss aversion, and the endowment effect, then gesture at how each might apply. What the paragraph cannot produce is the operator’s judgment about which of those framings actually changes outcomes in the field versus which ones are theoretically interesting but practically inert. That judgment only exists in someone who has watched both domains play out under real conditions. The technique compounds when the cross-domain insight has a one-way direction. Behavioral economics applied to plumbing produces uncopyable content. Plumbing applied to behavioral economics produces nothing useful, because the academic side has no operational gap that plumbing experience fills. The strongest cross-domain syntheses are the ones where one field has accumulated rigor and the other field has accumulated reps, and the synthesis transfers the rigor to the place that has the reps. Look for that asymmetry when you are choosing which two fields to cross.
How to Use the 12 Techniques
Treat them as a pre-publish checklist. A piece scoring above 0.5 IGS almost always uses 5 to 7 of these 12 techniques. Below 0.3 IGS almost always uses 0 to 2. Pick the techniques that fit your content type, your data access, and your willingness to be specific in public. The question to ask before publishing: could an LLM have written this without any of these techniques being applied? If yes, do not publish because you’re not creating enough helpful content or net new information gain for it to be of value.
What to Stop Doing
- Stop publishing comprehensive 101 guides. AI has already synthesized every fundamental topic. Your “Complete Guide to X” has been beaten to death, it’s not differentiation. Write the 102 or do not publish.
- Stop opening with credibility clichés. “Having spent 20 years in this industry” is what every author writes. AI has read a thousand of those openers. Credibility comes from the specifics that follow, not the years claimed. (Guilty of this on at least a dozen of my own posts. The audit is on the calendar.)
- Stop citing the patent without reading it. If you reference Google’s information gain patent in your content, link to the actual patent and describe what it actually says (session-level personalization, not global novelty). Most articles get this wrong, and it is becoming a citation liability as AI engines learn to weight authoritative sources.
- Stop publishing without an IGS check. If you do not know how differentiated your draft is from the top 10 ranking pages before you publish, you are guessing. The math is not optional anymore.
Frequently Asked Questions
What is information gain in SEO?
Information gain is the principle that AI search engines and modern Google reward content for adding new information to a topic rather than repackaging what already exists. The concept traces to a 2018 Google patent (US 11,354,342 B2) and a 2022 article that popularized it. In 2026 the framework has been refined by peer-reviewed research and is most useful as a content quality lens, not a confirmed ranking factor.
What is the difference between topical authority and information gain?
Topical authority and information gain measure different things. Topical authority is the breadth and depth of a publisher’s coverage across an entire topic. Google and AI engines reward sites that have demonstrably covered a subject from multiple angles over time. Information gain is the novelty of any single piece of content relative to existing content for the same query. The two reinforce each other. A brand with strong topical authority that publishes high-information-gain pieces compounds into citation dominance in AI Overviews and LLMs. A site with topical authority but no information gain gets crawled but absorbed into AI synthesis. A site with information gain but no topical authority struggles to be retrieved in the first place. Both matter.
How does AI search actually cite my content?
Through two completely separate mechanisms. The training-data path: when a new model is trained (typically every 6 to 18 months), your content gets crawled and embedded into the model’s permanent weights. The retrieval-augmented generation (RAG) path: AI Overviews, ChatGPT search, Perplexity, Claude search, and Copilot Search in Bing retrieve fresh content at query time using a separate embedding model, find matches via cosine similarity, and feed the top results to the LLM as context. The first path is slow and permanent. The second path can cite your content within hours of publication if it gets indexed.
What is the difference between AI training and RAG?
AI training is the process where embeddings are written into a model’s weights from a fixed dataset. Once training is complete, the embeddings are frozen and inference does not update them. Retrieval-augmented generation (RAG) is a separate runtime mechanism where current content is retrieved from a search index, embedded on the fly, and fed to the LLM as context for a single query. Most current AI search products (Google AI Overviews, ChatGPT search, Perplexity) use RAG for fresh information because the underlying LLM’s training cutoff is months or years old.
When will my content show up in AI search after I publish?
Through the RAG path: typically hours to days, depending on how quickly your content gets crawled and indexed by the search engine the AI product uses. Through the training-data path: typically 6 to 18 months, but only if your content was crawled into Common Crawl, GPTBot, ClaudeBot, or Google-Extended before the next model’s training cutoff date. Training cutoffs are typically several months before model release, so content published in the last quarter often misses the next release entirely. Most citations operators see today come from the RAG path because it is fast enough to react to recent publishing.
What is the difference between Googlebot, CCBot, GPTBot, and Google-Extended?
Each bot serves a different purpose and can be allowed or blocked independently in robots.txt:
| Bot | Owner | Path | What it powers |
|---|---|---|---|
| Googlebot | RAG (Path 2) | Google index, which powers AI Overviews, AI Mode, and Gemini grounding | |
| Bingbot | Microsoft | RAG (Path 2) | Bing index, which powers Copilot Search in Bing and ChatGPT search retrieval |
| CCBot | Common Crawl | Training (Path 1) | Common Crawl dataset that feeds GPT, Claude, Llama, and Falcon training |
| GPTBot | OpenAI | Training (Path 1) | OpenAI’s own targeted crawl beyond Common Crawl |
| ClaudeBot | Anthropic | Training (Path 1) | Anthropic’s own targeted crawl |
| Google-Extended | Training (Path 1) | Gemini training; opt-out signal separate from Googlebot | |
| PerplexityBot | Perplexity | Both | Perplexity’s own index (retrieval and training) |
| OAI-SearchBot | OpenAI | RAG (Path 2) | ChatGPT search retrieval supplement |
| Bytespider | ByteDance | Training (Path 1) | TikTok and Doubao training |
Most SEO teams audit Googlebot access carefully and never check the others, which means they have no idea whether their content is reaching LLM training corpora at all.
What is Information Gain Density?
Information Gain Density (IGD) is a Searchbloom framework that measures the count of distinct, original, attributable insights in a piece of content against the saturation level of competing top-ranked content for the same query. The 5-to-7 Rule is the empirical benchmark: most competitive topics in 2026 require five to seven distinct insights to credibly compete in AI search. The full framework, including the three criteria, the audit procedure, the failure modes, and the origin story, lives in the dedicated piece on Information Gain Density.
What are the types of information gain?
Searchbloom identifies twelve distinct types, called the 12 Information Gain Techniques: (1) proprietary aggregate data, (2) first-hand case studies, (3) subject matter expert quotes, (4) failure documentation, (5) named failure modes with cohort specificity, (6) pricing and economic transparency, (7) process and timeline transparency, (8) operational artifacts, (9) decision frameworks with explicit tradeoffs, (10) verbatim customer language, (11) contrarian framings and strong stances, and (12) cross-domain synthesis. Pieces that win in AI search typically use four to six of these techniques deliberately.
How do I add information gain to a blog post?
Apply the 12 Information Gain Techniques as a pre-publish checklist. The four highest-leverage moves: (1) add at least one direct subject matter expert quote (Searchbloom has measured an average 400% lift), (2) include proprietary data from your own operations (CRM aggregates, A/B test results, pricing distributions), (3) name specific failure modes you have witnessed with cohort precision, and (4) take a contrarian stance with primary-source evidence. Most blog posts use one technique by accident. Pieces that win in AI search use four to six deliberately. Run an Information Gain Score check against the top 10 ranking pages for your target query before publishing. If your score is below 0.5, rework the post.
What is the difference between information gain and long-tail keyword strategy?
Long-tail keyword strategy and information gain operate on different layers of SEO. Long-tail strategy is about query selection: targeting specific, lower-competition search phrases to capture intent that head-term competition crowds out. Information gain is about content quality: how much novel value any single piece adds to the topic regardless of which query you target. They are complementary. Targeting a long-tail keyword with low information gain still loses to higher-authority duplicates. Targeting a head term with high information gain may not get retrieved if conventional ranking signals are absent. The strongest content combines both: a query-aligned topic plus original insights that meet the 5-to-7 Rule for Information Gain Density.
What is the Information Gain Score (IGS) and how is it calculated?
The Information Gain Score is a mathematical formula for measuring how differentiated a piece of content is from the top-ranking pages for the same query. The formula is IGS = 1 minus the maximum cosine similarity between your document’s vector embedding and each top-ranking competitor’s vector embedding. A score near 0 indicates a near-duplicate. A score above 0.7 indicates substantial novelty. IGS is necessary but not sufficient for citation; topical relevance is also required.
What letter grade does my Information Gain Score translate to?
Searchbloom’s IGS letter grade scale maps the 0.0 to 1.0 score to 13 familiar grades from F to A+. F covers 0.00 to 0.20, the absorbed range where the page earns no AI citation share. D- through D covers 0.20 to 0.30, also absorbed. D+ through C+ covers 0.30 to 0.50, the modest tier where citation is marginal. B- through A- covers 0.50 to 0.70, the meaningful tier and the practical citation threshold. A covers 0.70 to 0.85 and A+ covers 0.85 to 1.00, both substantially novel. Cross the line at B- (IGS 0.50) to be a serious citation candidate; clear A- (0.65) to win citation slots reliably. A high grade is necessary but not sufficient: topical relevance must also hold.
How many original insights does a piece of content need to be cited in AI search?
For most competitive topics in 2026, a piece needs 5 to 7 distinct, original, attributable insights to credibly compete for citation in AI Overviews and large language models. Searchbloom calls this the 5-to-7 Rule. Each insight must be specific enough to quote, attributable to the publisher, and pass the test of being something an LLM could not have written from existing sources alone.
What is the single highest-leverage content move for AI search visibility?
Adding a direct quote from a subject matter expert in their own words. Searchbloom has measured an average 400% lift across AI Mode, AI Overviews, Copilot Search in Bing, LLM visibility, and organic Google rankings when a partner quote is added to a priority page. This is the highest-leverage move identified across Searchbloom’s partner-clients. Methodology: 25 Searchbloom engagements over a rolling 90-day window, comparing each priority page before and after the quote was added; visibility is a composite of GSC and Bing Webmaster Tools impressions plus Peec AI citation and mention tracking across AI Overviews, AI Mode, Copilot Search in Bing, ChatGPT, Claude, Gemini, and Perplexity.
Is information gain a confirmed Google ranking factor?
No. The Google patent often cited as proof, US 11,354,342 B2, describes a session-level personalization mechanism that filters redundant content for an individual user, not a global ranking signal that rewards globally novel content. Treat information gain as a useful framework for content strategy, not a verified ranking input.
How many sources do AI Overviews cite on average?
Roughly 10 links from about 4 unique domains, based on Surfer SEO’s analysis of 36 million AI Overviews from March to August 2025. The number scales with answer length: short AIOs cite about 5 sources, while long AIOs cite up to 28.
Does original research actually improve AI citation rates?
Yes, measurably. The Princeton GEO study published at KDD 2024 found that adding original statistics lifted citation visibility by 41% in position-adjusted word count, and adding quotations lifted it by 28%. Combined optimization produced up to 40% overall lift.
Is traditional SEO still relevant in the AI search era?
Yes. Ahrefs’ March 2026 analysis of 4 million AI Overview citations found that 38% of cited pages rank in Google’s top-10 for the original query, down from 76% in their July 2025 study. The remaining citations come increasingly from pages that rank for the sub-queries AI Overviews fan out to. Either way, conventional SEO is the floor that AI search visibility builds on. Sites that cannot rank for the head term or its fan-out variants do not get cited in AI Overviews at scale.
How does Reddit factor into AI search visibility?
Reddit overtook Wikipedia as the #1 AI citation source across most engines in 2025. Reddit citations in AI Overviews grew 450% between March and June 2025, and Perplexity cites Reddit roughly 24% of the time. Brands that want to be cited in AI search increasingly need a Reddit, YouTube, or LinkedIn presence in addition to owned content.
Where does information gain fit inside the MERIT Framework?
Information Gain Density flows through all five pillars of the MERIT Framework: Mentions, Evidence, Relevance, Inclusion, and Transformation. Evidence is where you author IGD most directly (quotes, statistics, proprietary research). Mentions delivers it through third-party content you didn’t author (reviews, earned media, Reddit, YouTube). Relevance elevates it through structural change (HTML passage hierarchy shifts the embedding). Inclusion makes it discoverable (without crawlability and indexation, IGD is invisible to AI engines). Transformation measures and compounds it over time. Treating IGD as Evidence-only misses where most of it originates and accumulates.
The Bottom Line
Information gain matters in 2026, but most articles describe it incorrectly and none of them tell you how much you actually need or how to measure it. The corrected framework has three operational pieces: Information Gain Density (count distinct original insights, target 5 to 7), the Information Gain Score (1 minus max cosine similarity to the top-ranking competitors, target above 0.5), and the highest-leverage move (a direct subject matter expert quote, which has produced an average 400% lift across Searchbloom’s partner-clients).
All three operate inside the MERIT Framework, which addresses Information Gain Density across all five pillars (Mentions, Evidence, Relevance, Inclusion, Transformation). Evidence is where you author it most directly, the others are where it originates, multiplies, manifests, and compounds. If you are evaluating agencies specifically for AI search readiness, our breakdown of the best AI SEO agencies walks through what to look for. If you want to know whether your priority pages clear the IGS threshold for the queries you are targeting, that is the work we do every day.
Information gain is one of six components of Corpus Engineering, the systems-level discipline for AI visibility. The other five are corpus accessibility, semantic structure, corpus expansion, retrieval optimization, and corpus maintenance.
