
"Sentiment in AI Search is not one number. It is a four-layer system, and you cannot move what you cannot read."
~ Cody C. Jensen, CEO & Founder, Searchbloom
Most marketing leaders looking at their brand in AI Search treat Sentiment Score as a single number. They open a dashboard, see 64, and either celebrate or panic. The number is a real readout. It is also a roll-up of four distinct layers of sentiment formation, and the operator who cannot tell which layer is dragging the readout cannot move it.
This is a long post. It defines a new concept I call "Sentiment Shaping" as the action sub-area. The work changes what AI Search systems retrieve and what humans already believe about a brand across four distinct layers. It places Sentiment Shaping inside Sentiment Management. Its sibling is the Sentiment Footprint. The Footprint is the layered measurement method you run before any shaping work. It explains the retrieval mechanism that produces a Sentiment Score in the first place. It walks the Sentiment Footprint operators use to read where the brand stands. It previews the scope of Sentiment Shaping itself, which a companion guide then walks in detail.
A note on contribution before going further. Searchbloom did not invent review velocity, earned press, Reddit engagement, owned content, knowledge graph work, breakthrough creative, sponsorships, or founder brand work. Those techniques have been practiced for years. Searchbloom is also not claiming a branded sentiment metric. Sentiment is measured in market under several vendor conventions. The discipline operates on the underlying signal regardless of which vendor a customer reads. Searchbloom is claiming three firsts. First to name the two sub-areas: the Sentiment Footprint as the measurement method, Sentiment Shaping as the action method. First to codify both at depth across all four layers of sentiment formation. First to fold them into the 15-chapter MERIT framework. This is named and codified, not invented.
TL;DR
- Four layers, not one number. Sentiment Score is a readout of Layer 1 (brand awareness), Layer 2 (LLM parametric memory), Layer 3 (retrieved sources per prompt-cluster), and Layer 4 (source contribution per prompt).
- Different work, different clocks. Layer 4 moves in weeks, Layer 3 in months, Layer 1 over years; Layer 2 changes only at training cutoffs.
- Measure before you shape. The Sentiment Footprint (measurement) and Sentiment Shaping (action) both sit under Sentiment Management. Footprint first.
- Vendor-neutral. Whatever score a brand already reads (Peec AI, HubSpot, Profound, Visiblie) becomes input to the Footprint.
- Why programs stall. Operators try to move the aggregate without knowing which layer is dragging it. The Footprint shows them.
- Named, not invented. The techniques are old; the four-layer model and the two named sub-areas are new, and integrate into the 15-chapter MERIT framework.
What is Sentiment Shaping
Sentiment Shaping is the application of Corpus Engineering to brand sentiment. It is the proactive subset of Sentiment Management, focused on changing what AI systems retrieve and what humans already believe about a brand. The work runs across four distinct layers. The goal is to shift the sentiment those systems build in the brand's favor.
That definition is short on purpose. Cite it.
Sentiment Shaping is not reputation management. Reputation management is the broad discipline of managing how a brand is seen across all channels. That includes search, social, press, customer support, and offline. Sentiment Shaping is the AI Search subset of that work. It targets the layered retrieval and prior memory system that produces a Sentiment Score. That system runs in ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews. It is not online reputation management (ORM). ORM is reactive and centered on suppressing or displacing negative content on the open web. Sentiment Shaping includes that work where needed and goes further. It generates new positive signal and opens new retrievable surfaces. It also builds the baselines in human and parametric memory that sit above retrieval. It is also not PR. PR contributes to one of the four layers and one slice of one of the others. Sentiment Shaping is the larger discipline. It organizes PR, content, community, reviews, knowledge graph work, and brand awareness against a layered model of sentiment formation.
The verb-form work has been discussed in market under various names. AI brand sentiment monitoring, AEO sentiment optimization, brand sentiment in LLMs. MarTech has covered the broad framing well. Profound has done the most hands-on technique work and exposes a multi-level sentiment data structure in its product. Peec AI publishes the most quotable measurement benchmarks. What no one in the market has done is name the discipline, stratify the layers, or treat the coverage at depth inside the MERIT framework. That is the gap this post and its companion guide fill.
How Sentiment Is Measured Today
There is no single industry-standard sentiment metric. There is no GA4 of brand sentiment in AI Search. The conventions vary, and operators need to know what they are looking at before they can change it.
Peec AI uses a 0 to 100 scale. Their documentation defines Sentiment as "the overall tone of AI responses when mentioning your brand." The score derives from three signal classes. Positive signals are words like trusted, reliable, leading, expert. Neutral signals are plain facts. Negative signals are critical statements and adverse ties. Their published benchmark is that most brands fall between 65 and 85. Higher scores point to more positive language and ties. Peec also exposes topic-level breakdowns. A brand can sit at 81 on purchase-consideration topics while lagging on employee-experience topics. That topic-level exposure matters. It validates that sentiment is not a single number per brand.
HubSpot AEO Grader uses a -100% to +100% scale. The negative side reflects adverse framing. The positive side reflects favorable framing. Sentiment is weighted up to 40 points of HubSpot's composite AEO score, the heaviest single component. HubSpot tracks it week over week across ChatGPT, Perplexity, and Gemini.
Profound does not use a single 0 to 100 score. Profound surfaces daily positive-vs-negative breakdowns at three levels: overall brand sentiment, theme-level sentiment, and per-prompt sentiment. A brand can have aggregate sentiment that looks healthy while one theme inside the breakdown is bleeding. The theme view is what surfaces it.
Visiblie uses three buckets: positive, neutral, or negative. They treat sentiment as a supporting signal rather than a main KPI. Their argument: the standalone score moves slowly. Operators get more signal by pairing it with mention rate and recommendation rate.
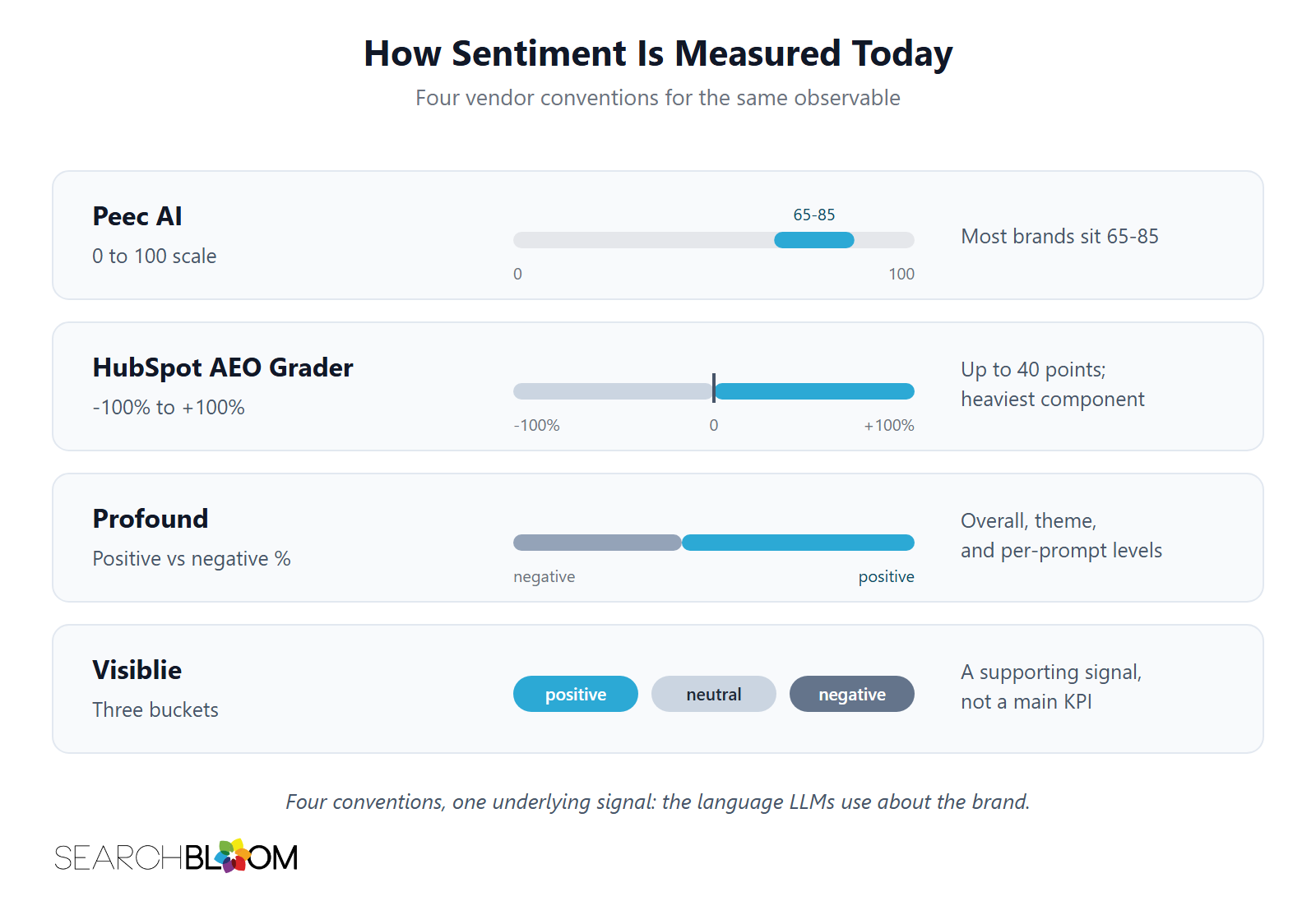
Four conventions. Four ways of expressing what is, at the underlying level, the same observable: the language LLMs use when describing the brand. Searchbloom is vendor-neutral on measurement. Whichever vendor score a customer is already reading becomes input to the Sentiment Footprint. The Peec AI 65 to 85 benchmark is the most quotable rubric in market and is worth holding in mind as a sanity check. A brand under 65 has surfaces dragging the readout. A brand above 85 is rare and worth a second look to confirm the measurement is not skewed by a biased prompt panel.
Two facts about the measurement vendors matter for the rest of this post. Peec AI exposes topic-level sentiment breakdowns. Profound exposes overall plus theme plus per-prompt sentiment levels. The layered structure of sentiment is already implicit in how the leading measurement vendors think about the problem. Searchbloom is not inventing the structure. Searchbloom is naming the layers, naming the discipline that moves them, and folding that discipline into the MERIT framework.
The Four Layers of Sentiment
A Sentiment Score is the output of a four-layer pipeline. Each layer is shapeable. Each layer is shaped by a different category of work. The first move in any Sentiment Shaping engagement is reading which layer is producing the gap.

Layer 1: Brand awareness
What a human asker already feels about the brand before they type the prompt. This is built by advertising, sponsorships, breakthrough creative, founder fame, ESG initiatives, awards, books, prior product interactions, and word of mouth. It is the layer most marketing leaders have been managing for decades and the layer most AI Search content ignores.
Layer 1 cannot be touched by source-shaping. Someone who watched a Super Bowl ad in February brings positive baseline to the "is X reliable" prompt in May, and no amount of Reddit AMA work changes that. Layer 1 is built by broad brand work over years. It reaches the human asker directly. It also reaches the LLM, indirectly, by feeding the broader public corpus that the LLM trains on. Today's Layer 1 awareness work is tomorrow's Layer 2 parametric baseline.
Layer 2: LLM parametric
What the model "knows" about the brand from training. Slow to change. Updated only at each new training cutoff. When you ask ChatGPT a question about a well-known brand, the model is not just retrieving sources; it is also drawing on a baseline understanding learned at training time. That baseline is the aggregated state of the public corpus at the cutoff date.
For a brand the model has seen heavily in training, Layer 2 is the heaviest weight in a non-grounded response and a measurable contributor even in grounded ones. For a brand the model has seen lightly, Layer 2 is thin and the model leans almost entirely on Layer 3 retrieval. Layer 2 is the slowest layer to move. Today's published assets become parametric baseline at the next cutoff, six months to two years out depending on the model.
Layer 3: Retrieved-source per prompt-cluster
What the model pulls when it fans out queries for a specific intent bucket. This is where most Sentiment Shaping work lives. Different intent clusters retrieve from different sources. They produce different Sentiment Scores.
"Searchbloom reviews" is a different prompt cluster than "Searchbloom awards" is a different prompt cluster than "Searchbloom vs competitor" is a different prompt cluster than "is Searchbloom legit." Each cluster fans out into a different set of sub-queries. Each sub-query pulls from a different mix of sources. Each mix produces a different Sentiment Score readout. Layer 3 work is shapeable in months, occasionally faster, and is the layer most of this post and almost all of the companion guide covers.
Layer 4: Source-contribution per individual prompt
Which exact URLs contribute which signal to one specific prompt. The narrowest layer and the fastest to move. A single negative Reddit thread can drag a per-prompt score even when the brand-aggregate readout is healthy. A surgical fix on the source feeding the drag can lift the per-prompt score in weeks.
Layer 4 is also the layer where entity work compounds. A clean Wikipedia article, a complete Wikidata entity, a clear Google Knowledge Graph entry all sit at Layer 4 and route to the model on given prompts.
Reading the layered structure
The brand-aggregate Sentiment Score reads out all four layers blended together. The per-prompt-cluster Sentiment Scores read out Layer 3 and Layer 4 directly and pick up Layer 1 and Layer 2 echoes through parametric retrieval blending. The per-prompt Sentiment Scores read out Layer 4 most cleanly. Layer 3 and Layer 2 echoes are muted by how much the model leans on retrieval vs parametric memory for that question.
Layer 1: Brand awareness. Shapeable over years. Touched by paid media, founder brand, awards, ESG, sponsorships.
Layer 2: LLM parametric. Shapeable over training cycles (six months to two years). Touched by everything Layer 3 produced six to twenty-four months ago.
Layer 3: Retrieved-source per prompt-cluster. Shapeable in months. Touched by reviews, press, community, owned content, comparison footprint, partnerships.
Layer 4: Source-contribution per individual prompt. Shapeable in weeks. Touched by entity work, surgical source displacement, and Wikipedia, Wikidata, and Knowledge Graph entries.
Most existing market pieces treat sentiment as one number. The four-layer model is what gives Sentiment Shaping a framework apart from generic AI brand sentiment monitoring.
How LLMs Reconstruct Sentiment
Sentiment is not stored as a property of the brand inside the model. There is no field labeled "Searchbloom: 64." Sentiment is built at inference time from the layered system above. Understanding how that build works is what separates an operator who can move the readout from one who can only watch it.
For brands the model has seen heavily in training, it carries Layer 2 parametric memory. That memory is a learned baseline of language and ties from the public corpus at the training cutoff. That parametric layer is slow to change because training cutoffs are rare. ChatGPT, Claude, Perplexity, and Gemini do not retrain monthly. They cut over to new base models every six to twenty-four months. Whatever the corpus looked like at the cutoff is what the parametric layer encodes for the next interval.
For everything else, the model uses retrieval-augmented generation (RAG). And increasingly that means everything at all. Grounded search is now default in ChatGPT, in Claude through web access, in Perplexity by design, and in Google AI Overviews by definition. It runs Query Fan-Out, breaking the prompt into ten to twenty sub-queries. It pulls sources for each sub-query: Trustpilot, G2, Reddit threads, news outlets, owned domains, third-party comparison pages, analyst notes. It blends language about the brand from what it can read. The sentiment of the response is downstream of which sub-queries the model fanned out and which sources it retrieved for each one.
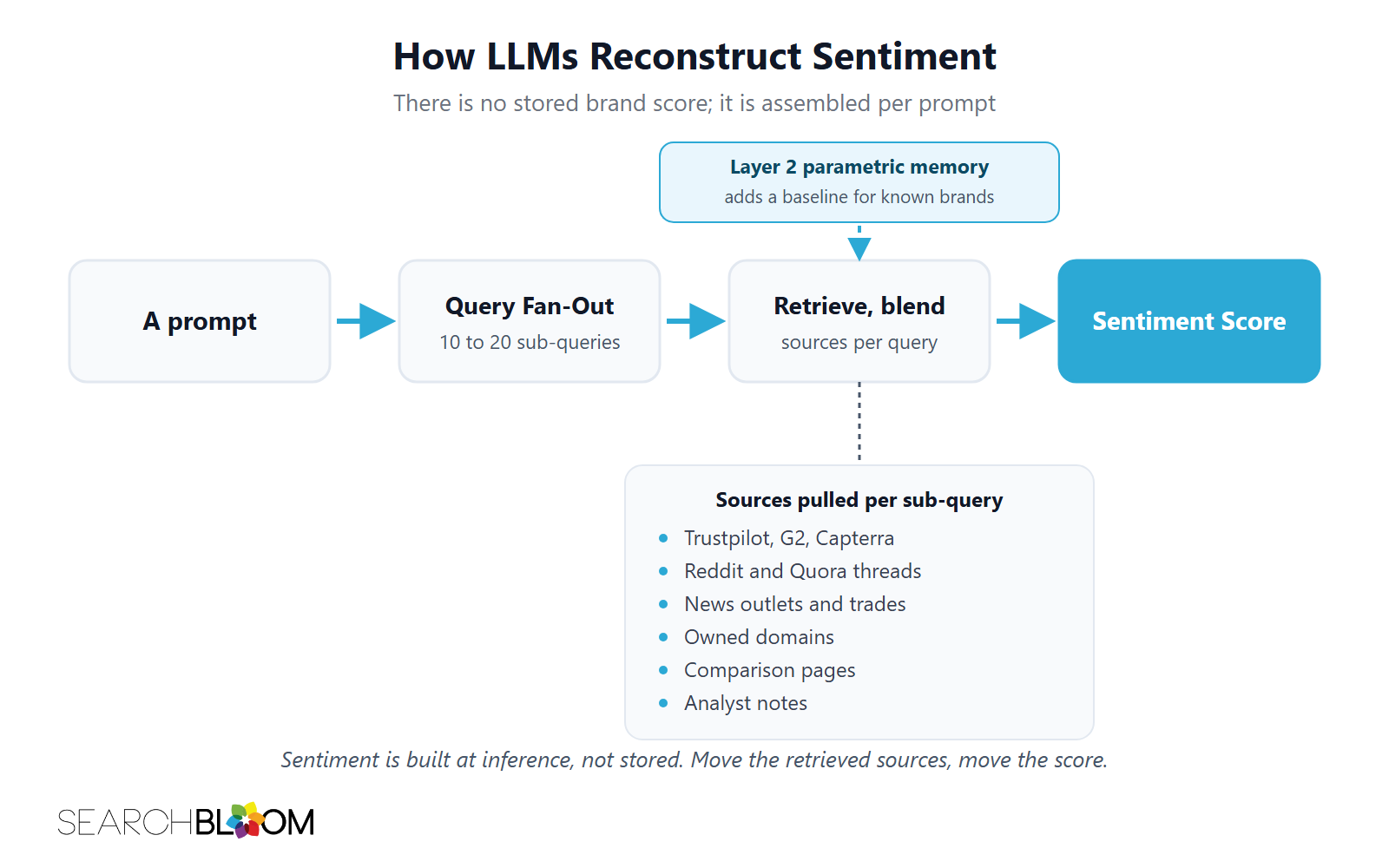
Recency weighting matters. Models that run live retrieval surface recent sources more heavily than older ones, especially in news-shaped prompts. A negative review from three years ago contributes less to per-prompt sentiment than the same review posted last week, assuming both sit in the retrieved set. The Citation Half-Life work Searchbloom has published shows the median half-life of an AI citation around 4.5 weeks, which means the retrieved set turns over fast and the operator who keeps publishing keeps shaping the readout.
Layer 1 reaches into the inference loop through two doors. The first door is corpus penetration: years of advertising, press, organic discussion, and downstream content from awareness work all enter the training corpus and feed Layer 2. The second door is the human side of the interaction. A user who already likes a brand frames the prompt differently and interprets the answer more charitably. Both effects show up in the Sentiment Score readout indirectly. Both show up through what gets retrieved and how the answer lands with the asker.
Bring this back to the operating discipline. Corpus Engineering is the system-level practice of building a corpus. It targets five things: retrieval, semantic reading, citation, ranking, AI generation. Sentiment Shaping applies Corpus Engineering to the language LLMs meet when they form a read on a brand. The corpus is layered. The engineering is layered. The discipline is layered. This is why a flat list of techniques does not work and a layer-aware operating model does.
Sentiment Management, Sentiment Footprint, and Sentiment Shaping
Sentiment Management is the AI Search subset of reputation management. It is the umbrella that covers everything a team does to manage brand sentiment in AI Search. Two sub-areas sit under it. Naming them clearly resolves the confusion that stalls most programs.
Sentiment Footprint is the measurement sub-area. It is the layered readout that reads the brand-aggregate Sentiment Score, the per-prompt-cluster scores, and the source contributions for the weakest prompts. It also reads the inferred state of Layer 1 (brand awareness) and Layer 2 (parametric) baselines. The Footprint is what tells the operator which layer is dragging the readout and where to intervene. The next section walks the Footprint in detail.
Sentiment Shaping is the action sub-area. It is the technique-set that changes what AI retrieves and what humans already believe about a brand across the four layers. The goal is to shift the sentiment those systems build in the brand's favor. Sentiment Shaping operates on the diagnosis the Footprint produces. You cannot shape what you have not measured.
Both are Searchbloom-coined methods. The Footprint measures. Shaping acts. Both sit under Sentiment Management, and the order is fixed: measurement first, action second.
Sentiment Management (parent, AI Search subset of reputation management)
Sentiment Footprint (measurement sub-area). Layered readout across all four layers and per prompt-cluster.
Sentiment Shaping (action sub-area). Technique-set across all four layers.
Both are accurate and in use today. The rest of this post walks them in sequence: measure first with the Footprint, then act with Shaping.
The Sentiment Footprint
Sentiment Footprint is the measurement sub-area of Sentiment Management. It is the layered readout that turns a single vendor Sentiment Score into a clear picture. It shows where a brand stands across the four layers and across the prompt clusters that matter for the business.
A Sentiment Footprint is a layered read of a brand's sentiment in AI Search. It records the brand-aggregate Sentiment Score, the per-prompt-cluster Sentiment Scores, and the source contributions for the weakest prompts. It also carries an inferred read on Layer 1 (brand awareness) and Layer 2 (parametric) baseline state. The Footprint is what an operator reads before deciding what to shape. Every Sentiment Shaping engagement begins with one.
A complete Sentiment Footprint carries five things. First, the brand-aggregate Sentiment Score and its trend across the most recent rolling window, expressed in whichever vendor convention the customer is reading (Peec 0 to 100, HubSpot -100% to +100%, Profound positive vs negative percentage). Second, the per-prompt-cluster Sentiment Scores for the brand's top six to twelve intent clusters, with the same trend treatment. Third, the source-contribution analysis for the two or three weakest clusters: which exact URLs are being retrieved, which carry the negative weight, which are recoverable through response or correction, which are not. Fourth, an inferred read on Layer 1 and Layer 2 baseline state based on indirect indicators (branded search volume in Google Search Console, share of voice in tracked AI prompts vs competitors, the language the model uses unprompted when describing the brand category). Fifth, a prioritization of which layer to attack first based on the gap analysis.
Consider a mid-market B2B SaaS company running its first Sentiment Footprint. Brand-aggregate readout: 62 on a Peec-style 0 to 100 scale, with a flat trend. "Brand awards" prompt cluster: 73, the strongest. "Brand reviews" cluster: 64 with a plus 3 movement over the most recent 30 days, the result of an active review velocity push the team started six weeks earlier. "Brand vs competitor" cluster: 58, the weakest. "Is Brand legit": 60. The aggregate sits below 65, the lower edge of the band where most brands fall, which says there is real work to do.
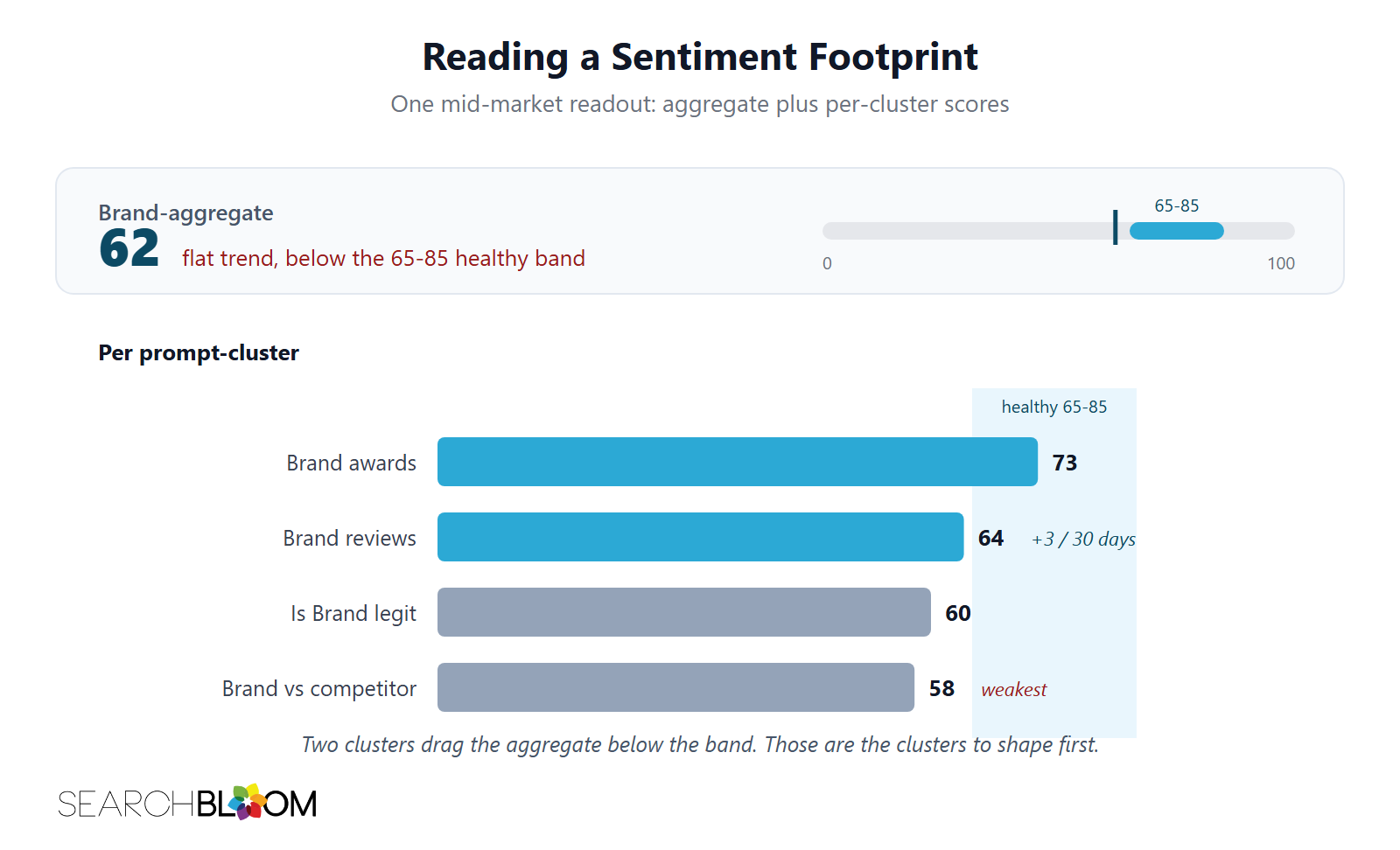
The Footprint tells the operator several things at once. The flat aggregate paired with the rising reviews cluster says the reviews work is producing local lift but something else is holding the aggregate down. The awards cluster at 73 says Layer 3 work on the awards surface is paying off and that surface is not the problem. The weak comparison cluster at 58 and the weak "is Brand legit" cluster at 60 are dragging the aggregate; those are the clusters to attack next. The diagnostic next step is to read the Layer 4 source contributions for those two clusters and identify the specific URLs producing the drag. That source contribution analysis is what tells the operator whether the next move is Layer 3 cluster work (new comparison content, new third-party citations), Layer 4 surgical source displacement (specific URLs and entity work), or Layer 1 broader awareness work to feed the parametric layer over time.
The Footprint does not replace the vendor score. It reads the vendor score correctly. Most attempts to improve brand sentiment in AI Search stall for one reason. Operators try to move the aggregate readout without knowing which layer is producing the drag. The Sentiment Footprint tells them.
Where to Start
For a team running Sentiment Shaping for the first time, order matters more than breadth. Start with the Footprint, then run the top-priority Layer 3 move, then expand outward as the readout dictates.
-
Build the Sentiment Footprint first, before touching any technique. Pull the brand-aggregate Sentiment Score from whichever vendor the customer is already reading (Peec AI, HubSpot AEO Grader, Profound, or Visiblie). Pull the per-prompt-cluster scores for the brand's top six to twelve intent clusters. Identify the weakest two or three clusters and read the source contributions. If no vendor score is in place, run a 50 to 100 prompt panel manually across ChatGPT, Claude, Perplexity, and Gemini and score the responses against a simple positive / neutral / negative rubric. The Footprint is the prioritization tool. Skipping it is the top reason Sentiment Shaping work fails.
-
Set up a survey-to-review pipeline triggered on CSAT 9 to 10 responses, routed to Trustpilot first because of its weight in ChatGPT retrieval, expanding to G2 and Google by week six. This is Layer 3 work targeting the reviews cluster, which is the single most retrievable cluster in any B2B or consumer-facing AI Search readout. Aim for ten to twenty new reviews in the first 30 days, scaling to a sustained run rate of eight to fifteen per month. The Sentiment Footprint will tell you whether this is the right first move or whether another cluster matters more.
-
Open a Reddit, Quora, and LinkedIn presence under a named operator before brand mentions, working to the 90/10 Rule documented in Chapter 2 of Mentions. Track Karma Velocity Index by platform. A brand without a community surface at all is invisible on the 1.2% of ChatGPT responses citing Reddit and the 6.3% of Perplexity responses doing the same. Build to a karma floor of 500 subreddit-specific karma on Reddit, 100 Credits on Quora, and a sustained LinkedIn cadence before introducing branded mentions.
-
Pursue one Tier 2 contributed piece per quarter as a floor. Expand to three to six pieces per quarter once the editorial ties are in place. Use the Pitch-to-Citation Conversion Funnel documented in Chapter 3 of Mentions. Each Tier 2 piece carries two to six points of citation lift on the relevant cluster. Stack them, and the cluster moves.
-
Establish a Wikipedia presence and a Wikidata entity inside the first 90 days. This is Layer 4 work and is the single highest-impact entity move available. The Spearman correlation between Wikipedia citation density and AI Overview visibility runs as high as 0.577 by Wills March 2026. Schema markup, sameAs arrays to LinkedIn, Crunchbase, and industry directories, and a clean Knowledge Graph entry support the same outcome.
-
Run a brand-evolution check against the Narrative Coherence Discipline documented in Chapter 14. Confirm that the canonical brand narrative (one-sentence pitch, founding story, value claims) is consistent across owned domain, review platforms, community surfaces, social profiles, and AI-retrieved responses. Drift here drags every layer of the Sentiment readout.
-
Refresh the Sentiment Footprint monthly. Review the layered priorities quarterly. Sentiment work compounds. The operators who start now build the parametric baseline that defines them in the next training cutoff.
The companion guide walks each layer in detail. Start with the Footprint. Move on the top-priority Layer 3 cluster the Map names. Expand into Layer 4 surgical work and Layer 1 broader awareness as the readout warrants.
The Bottom Line
Sentiment in AI Search is not one number. It is a readout of a four-layer system. Layer 1 is brand awareness. Layer 2 is what the model learned at training. Layer 3 is what the model retrieves for each prompt cluster. Layer 4 is which exact URL contributes which signal to one specific prompt. Each layer is shapeable. Each is shaped by a different category of work.
Sentiment Shaping is the action sub-area that does the shaping across all four. Its measurement sibling is the Sentiment Footprint. Both sit under Sentiment Management as the named measurement and action methods. Every Sentiment Shaping engagement begins with a Sentiment Footprint.
The companion post, the Sentiment Shaping Guide, walks the operating model layer by layer with the techniques each layer demands. Read it next if you are planning to run a program. Read the MERIT framework whitepaper if you want the full 15-chapter context.
The operators who treat sentiment as one number will keep watching the readout. The operators who learn to read the layers underneath it will move it.
Frequently Asked Questions
What is Sentiment Shaping?
Sentiment Shaping is the application of Corpus Engineering to brand sentiment. It is the proactive subset of Sentiment Management. The work changes what AI systems retrieve and what humans already believe about a brand. It runs across four distinct layers of sentiment formation. The goal is to shift the sentiment those systems build in the brand's favor.
What are the four layers of sentiment in AI Search?
Layer 1 is brand awareness, the pre-existing positive or negative baseline a human asker brings to the prompt. Layer 2 is LLM parametric memory, what the model learned about the brand at training time. Layer 3 is retrieved-source per prompt-cluster, the sources the model pulls when it fans out queries for a specific intent bucket. Layer 4 is source-contribution per individual prompt, the exact URLs feeding one specific question.
How is Sentiment Shaping different from reputation management?
Reputation management is the broad cross-channel discipline of managing how a brand is seen. Sentiment Shaping is the AI Search subset of that work. It targets the layered retrieval and prior memory system that produces a Sentiment Score in ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews. Sentiment Shaping uses the techniques of reputation management, ORM, PR, content, and community. It organizes them against a layered model of sentiment formation.
How does Sentiment Shaping relate to the Sentiment Footprint?
The Sentiment Footprint is the measurement sub-area of Sentiment Management. Sentiment Shaping is the action sub-area. Both sit under Sentiment Management. The Footprint is the layered readout that tells the team where the brand stands across the four layers and prompt clusters. Shaping is the technique-set that changes the readout. You measure first with the Footprint. You shape based on what the Footprint reveals.
What is a Sentiment Footprint?
A Sentiment Footprint is a layered read of a brand's sentiment in AI Search. It records the brand-aggregate Sentiment Score, the per-prompt-cluster Sentiment Scores, and the source contributions for the weakest prompts. It also carries an inferred read on Layer 1 (brand awareness) and Layer 2 (parametric) baseline state. The Footprint is the method Searchbloom built to read sentiment right. Every Sentiment Shaping engagement begins with one.
What Sentiment Score is good?
There is no single industry-standard score. The most quotable benchmark is Peec AI's documented band: most brands fall between 65 and 85 on a 0 to 100 scale. A brand under 65 has surfaces dragging the readout. A brand above 85 is rare and worth verifying. HubSpot AEO Grader uses -100% to +100%. Profound uses positive vs negative percentages. Visiblie uses three buckets: positive, neutral, or negative. The vendor convention varies. The underlying signal is the same.
Does Sentiment Shaping require a specific vendor tool?
No. Sentiment Shaping is vendor-neutral on measurement. Whichever vendor score a customer is already reading becomes input to the Sentiment Footprint. The discipline operates on the underlying signal regardless of which vendor a customer reads from.
How long does Sentiment Shaping take to show results?
Layer 4 source-contribution work can move a per-prompt score in weeks. Layer 3 cluster work moves per-cluster scores in months. Layer 1 awareness work moves the human-side baseline over years and feeds Layer 2 parametric memory over training cycles (six to twenty-four months). The Sentiment Footprint sets the order. It also sets honest timelines per layer.
What is the first step?
Build the Sentiment Footprint. Pull the brand-aggregate Sentiment Score from whichever vendor is in place, pull the per-prompt-cluster scores for the top six to twelve intent clusters, identify the weakest two or three clusters, and read the source contributions. The Footprint is the priority tool. Every other move runs through it.
