
Vector Dilution is the failure mode where a page covers so many topics that its whole-page embedding is averaged toward the consensus center of the ranking set, collapsing its measurable differentiation even when individual sections are genuinely novel. It is the opposite of Vector Shift, and it is the most common reason a thorough, expert, well-researched page still gets absorbed into an AI answer instead of cited by it.
Vector Dilution is the framing Searchbloom applies to SEO, AI citation, content consolidation, and information gain measurement. The underlying averaging effect is established in information retrieval; what was missing for SEO was a name, a mechanism, and a measurement. This guide gives it all three: what it is, the geometry that causes it, how to measure it on your own pages, what causes it in practice, and the two ways to reverse it. Naming a real, unnamed mechanism is itself an act of information gain, which is the point of the concept it describes.
What Vector Dilution is
The definition
Vector Dilution is the loss of measurable differentiation that happens when a page's single whole-page vector is pulled toward the center of the ranking set because the page covers too much shared ground. The page can contain genuinely original sections and still read, at the document level, as a near-duplicate of everything else ranking, because the document-level score is an average and the average is dominated by the shared bulk.
The one line to remember
Depth makes you complete. Information gain makes you necessary. Vector Dilution is what happens when you chase the first and lose the second. Google and the answer engines already have complete. They are short on necessary, and a diluted page gives them more of what they already have.
Why it is the exact opposite of Vector Shift
Vector Shift is the deliberate motion of your page's embedding away from the consensus center into open space, where it is distinct enough to be retrieved and cited. Vector Dilution is motion in the other direction along the same axis: back toward the center, into the crowd. They are not different phenomena. They are opposite signs of the same vector. Every editorial decision either shifts a page out or dilutes it in, and most "make it more complete" decisions dilute.
Why the phenomenon went unnamed until now
The averaging effect is not a new discovery. Information retrieval has known since the 1990s that one vector represents a multi-topic document poorly, and the idea of scoring a candidate by its marginal contribution rather than its standalone relevance goes back to Maximal Marginal Relevance, introduced by Carbonell and Goldstein in 1998. There is even a cousin term in another field: in GPS, dilution of precision describes how a poor geometry of satellites degrades a position fix. What was missing in SEO was a name for the content version of the problem: the specific, avoidable failure of a page diluting its own differentiation by trying to cover too much. Without a name, a team cannot brief against it, cannot measure it, and cannot argue about whether a given edit is making it worse. Naming it is what turns a vague unease about long pages into a decision you can make on every section.
The mechanism: how a page averages itself to the center
Your page is one point, not many
A search engine or AI retrieval system represents your page as a vector, a single point in a high-dimensional semantic space. That point is computed from the page's text, and when the text spans many subtopics, the point is effectively the average of all of them. You may experience your page as a sequence of distinct sections. The model experiences the whole-page representation as one coordinate.
The mean of many directions lands in the middle
Here is the geometry that does the damage. If a page covers one tight idea, its vector sits where that idea lives, which may be far from the consensus. If a page covers a dozen ideas, its vector is the mean of a dozen directions, and the mean of many directions points at the middle. The middle of a topic is the consensus center, the precise location every competing page already occupies, because they are all averaging the same shared subtopics. So the more subtopics you add, the more your whole-page vector converges on the one coordinate guaranteed to be undifferentiated.
A worked example
Picture a page with ten sections. Two of them are genuinely novel and sit far out in open space. Eight of them cover the standard ground every competitor covers, clustered at the center. The whole-page vector is the weighted average of all ten, so it sits eight-tenths of the way toward the center. Now add five more "for completeness" sections, all standard. The page is more thorough, more helpful, and more diluted: the average is now thirteen-fifteenths of the way to the center, and the two novel sections have even less influence on the document vector than before. You improved the page and worsened its differentiation in the same edit.
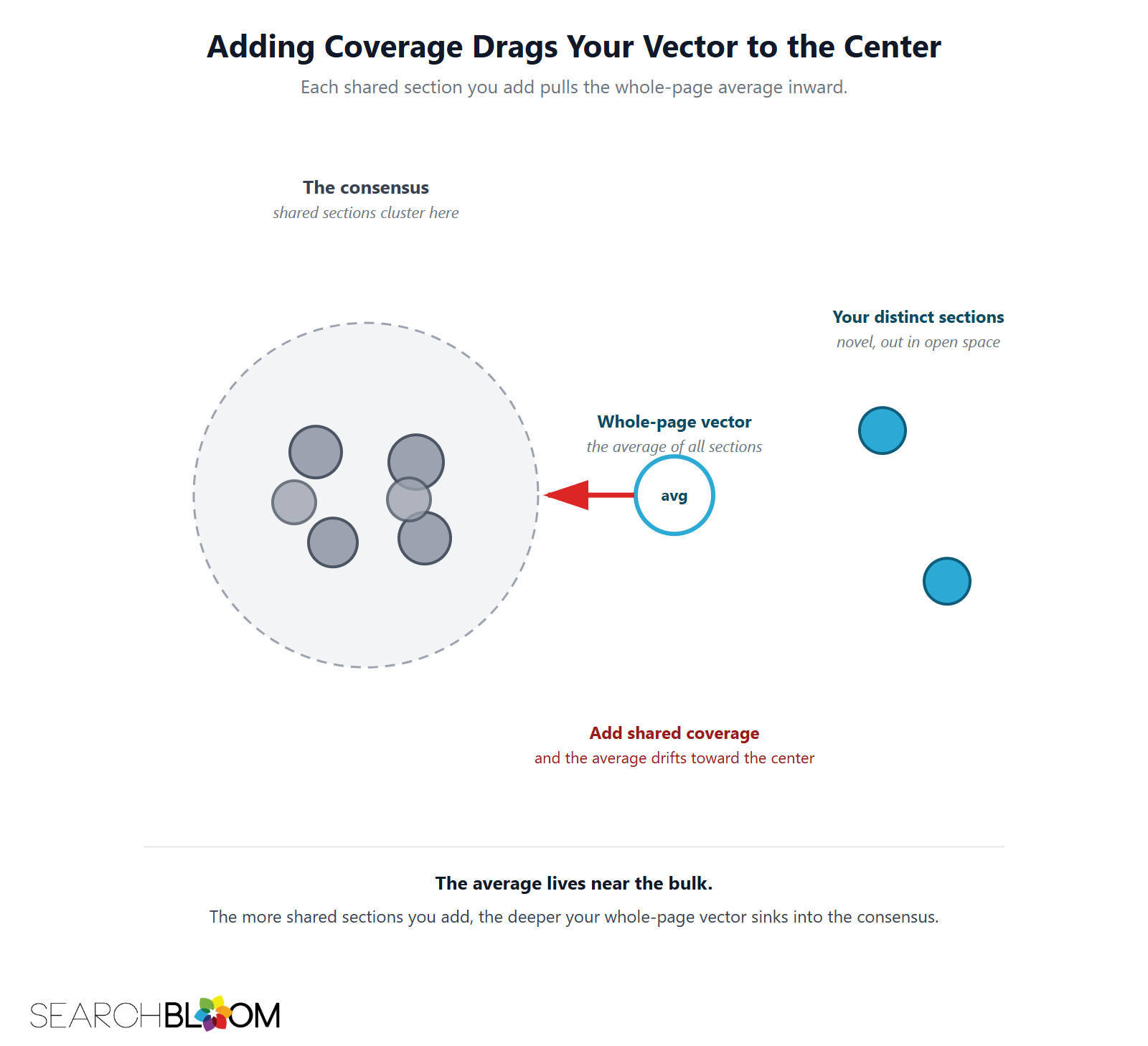
The math, in plain terms
The whole-page vector is, to a close approximation, the mean of the page's section vectors. The mean of a set of points is the centroid: the single point that minimizes total distance to all of them, and by construction the centroid sits inside the densest part of the set. If most of your sections cluster at the consensus, the centroid sits in that cluster no matter how far the remaining sections reach. The Information Gain Score is one minus the maximum cosine similarity between that centroid and the ranking pages, so a centroid inside the cluster scores near zero. The distinct sections still exist as individual points; they simply have almost no pull on where the centroid lands. That is the entire mechanism in one sentence: an average cannot represent its outliers, and your differentiation lives in the outliers.
Why query-weighting makes it worse
Modern scoring does not weight every section equally. It up-weights the sections most relevant to the query, because relevance to the query is what retrieval rewards. But the sections most on-query are usually the most conventional ones, the direct answer everyone gives. So query-weighting pulls the whole-page vector even harder toward the consensus, and the off-query sections where your originality often lives count for even less. The page is optimized into the center by the very mechanism meant to keep it relevant.
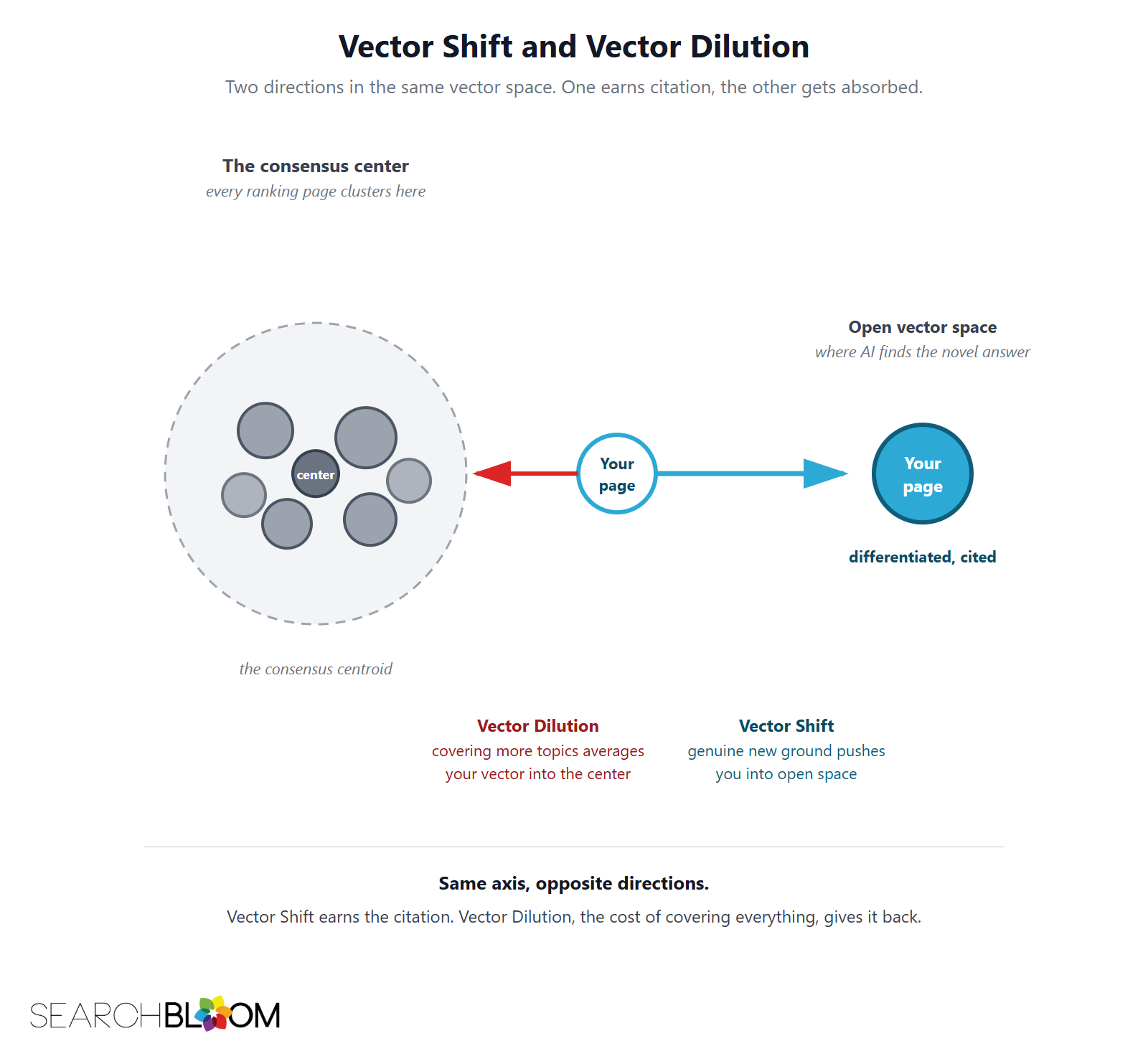
The proof it is real
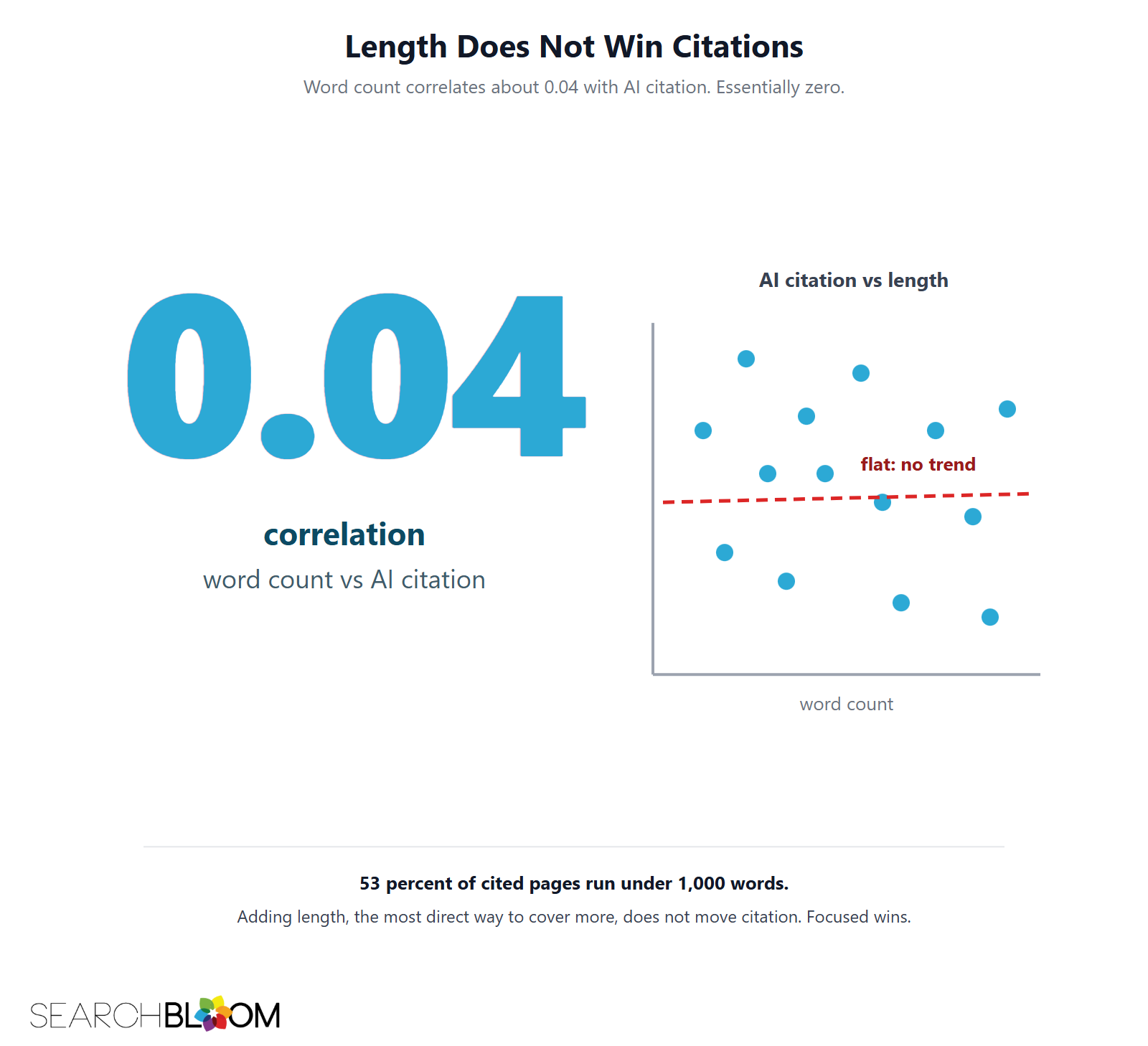
Word count barely correlates with citation
If completeness won, length would correlate with citation. It does not. Ahrefs analyzed 174,048 pages against 560,346 AI Overviews and found word count correlates about 0.04 with citation, which is statistically indistinguishable from zero. Adding words, the most direct expression of "cover more," does not move citation. (Source: Ahrefs short-vs-long content in AI Overviews study.)
Most cited pages are short
In the same dataset, 53 percent of cited pages run under 1,000 words. The pages winning AI citations are not the exhaustive mega-guides. They are focused pages whose vector sits somewhere distinct, with a self-contained answer that survives extraction. Short and sharp beats long and complete, which is exactly what the dilution mechanism predicts.
Why the skyscraper era ended
The skyscraper technique, build the longest most complete page on the topic, was a link-era strategy that worked when comprehensiveness signaled effort and earned backlinks. In a vector-retrieval world it is actively counterproductive, because each section added to out-cover a competitor pulls your page deeper into the shared center. The instinct that used to win now dilutes. Coverage and differentiation were always different axes; AI retrieval made the difference measurable and decisive.
Why AI answer engines amplify Vector Dilution
Vector Dilution always mattered for retrieval, but AI answer engines make it decisive, because of how they assemble an answer.
Query fan-out splits your page apart
Google's AI Mode and the other answer engines do not run one query against your page. They decompose the question into many sub-queries and retrieve passages for each, a process called query fan-out. A diluted page has one muddy whole-page vector and few distinct passages, so it surfaces for fewer of the fanned-out sub-queries than a set of focused pages would. The mega-page that looked comprehensive to a human is, to the fan-out, a single weak candidate instead of many strong ones.
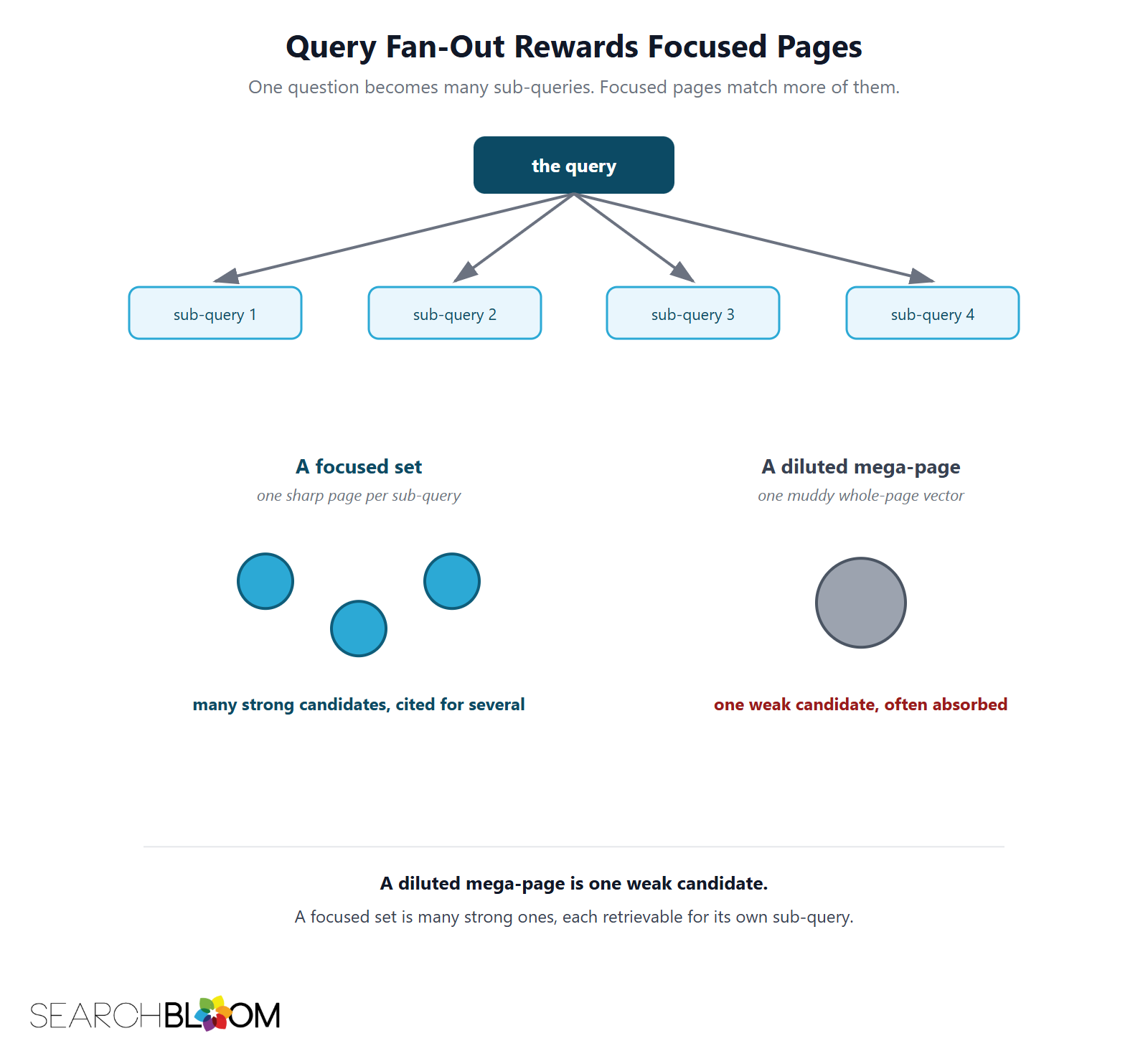
Synthesis rewards the marginal source
Once an engine has retrieved several passages, it synthesizes one answer and tends to cite the sources that each add something the others do not. That is a marginal-contribution test, and a diluted passage, sitting where the consensus already sits, adds nothing marginal. It gets read into the synthesis and left uncited. The page that contributes a fact or framing none of the other sources have is the one that earns the citation.
The diluted page is the one that gets absorbed
This is the practical stake of Vector Dilution in 2026. The absorbed-without-citation outcome, your content informing the answer while a competitor gets named, is the signature failure of a diluted page. It was retrievable enough to be read and undifferentiated enough to be uncredited. Differentiation is what converts being read into being cited.
A first-party example: this topic's own pillar
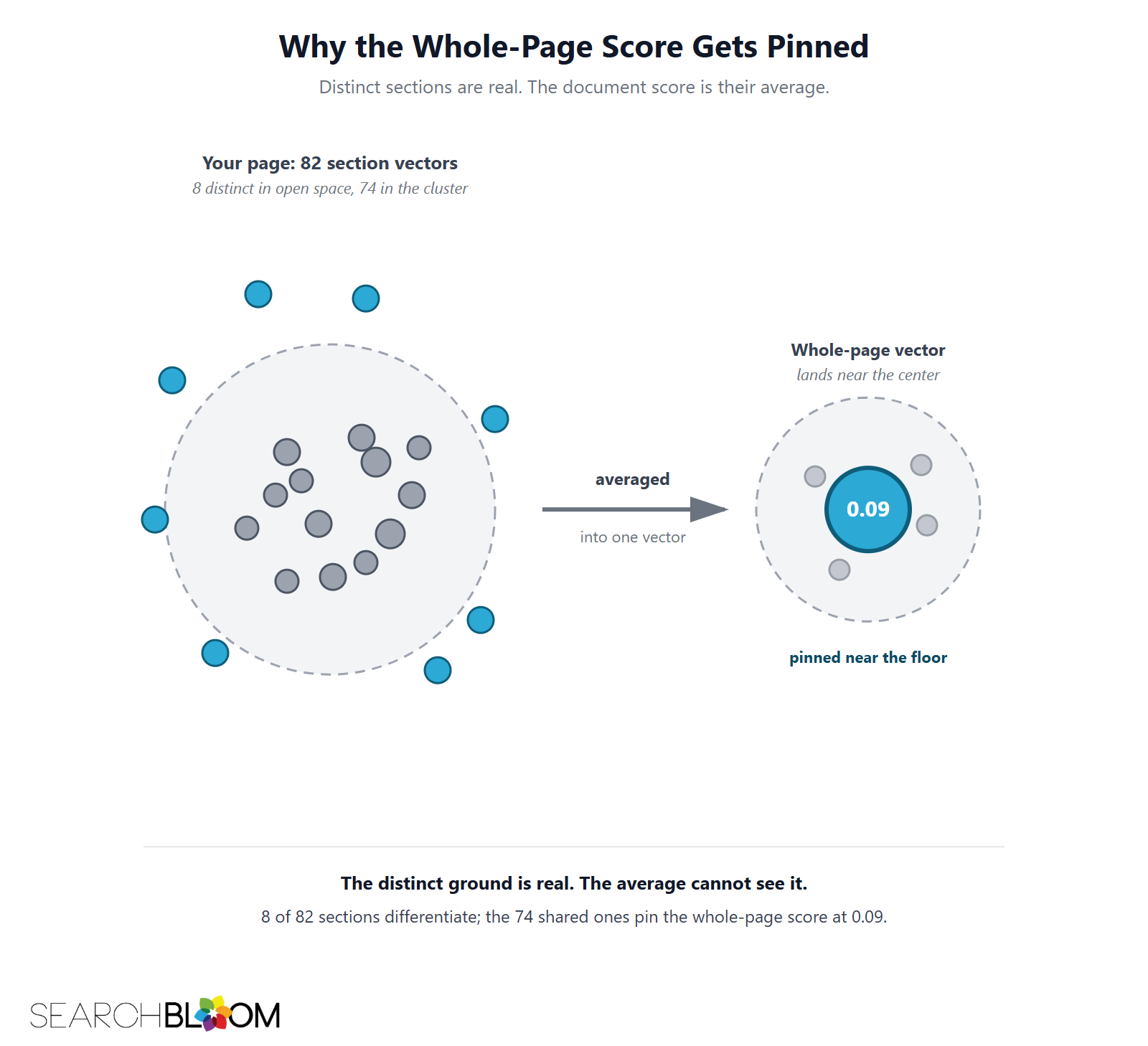
8 of 82, pinned at 0.09
We measured Vector Dilution on our own most comprehensive page. Searchbloom's Information Gain SEO guide, a deliberately exhaustive pillar, scores 8 distinct sections out of 82 on our Information Gain Score tool, with a whole-page score of about 0.09, near the floor. Eight sections say something no ranking competitor does. The other 74 cover ground the topic genuinely requires, and they average the whole-page vector down to 0.09.
What the number does and does not mean
The number does not mean the pillar is weak. It means the whole-page score is the wrong headline for a pillar, because the pillar's job is breadth and breadth dilutes by definition. The distinct-section count, eight passages that exist nowhere else, is the gain that actually earns citations, and it is invisible to the document-level average. This is the practical lesson of Vector Dilution: stop reading the whole-page score as a grade, and start reading the distinct-section count as the asset.
What causes Vector Dilution in practice
The "complete guide" brief
The single most common cause is a content brief that instructs the writer to cover everything: every subtopic, every related question, every angle a competitor touched. That brief is a recipe for the center. It guarantees the page averages across the full shared subtopic set, and it leaves no instruction to develop anything distinct. The brief optimizes for coverage, which is the axis that dilutes.
Consolidating pages for "efficiency"
Merging several focused pages into one mega-page is often sold as consolidation. Geometrically it is the opposite of helpful. Three sharp pages had three distinct vectors in three regions of open space. Merge them and you get one vector that is the average of all three, sitting closer to the center than any of them did alone. Consolidation trades three differentiated points for one diluted one.
Topic creep over time
Pages dilute slowly. A page launches focused, then over months accumulates "while we are at it" additions, an FAQ here, a related-topic section there, a paragraph answering a tangential question a customer asked. Each addition is reasonable on its own. The cumulative effect is a page whose vector has drifted from a distinct launch position into the center, with no single edit to blame.
Adding coverage to "strengthen" a slipping page
When a page loses visibility, the reflex is to add to it: more sections, more depth, more coverage, to signal quality. If the loss was caused by dilution, this deepens the problem. You respond to a centering page by pushing it further to the center. The page gets longer, the team feels productive, and the differentiation keeps falling.
Bolting on sections that restate the corpus
Sections added for SEO completeness, the "what is X," the "benefits of X," the boilerplate FAQ that repeats the consensus answer, are pure dilution. They add tokens that sit exactly where every competitor already sits, dragging the average in without contributing a distinct point. If a section says only what the ranking set already says, it is not neutral. It is a weight pulling you toward the center.
Vector Dilution and the skyscraper technique
The clearest way to understand Vector Dilution is to see what it does to the most popular content strategy of the last decade.
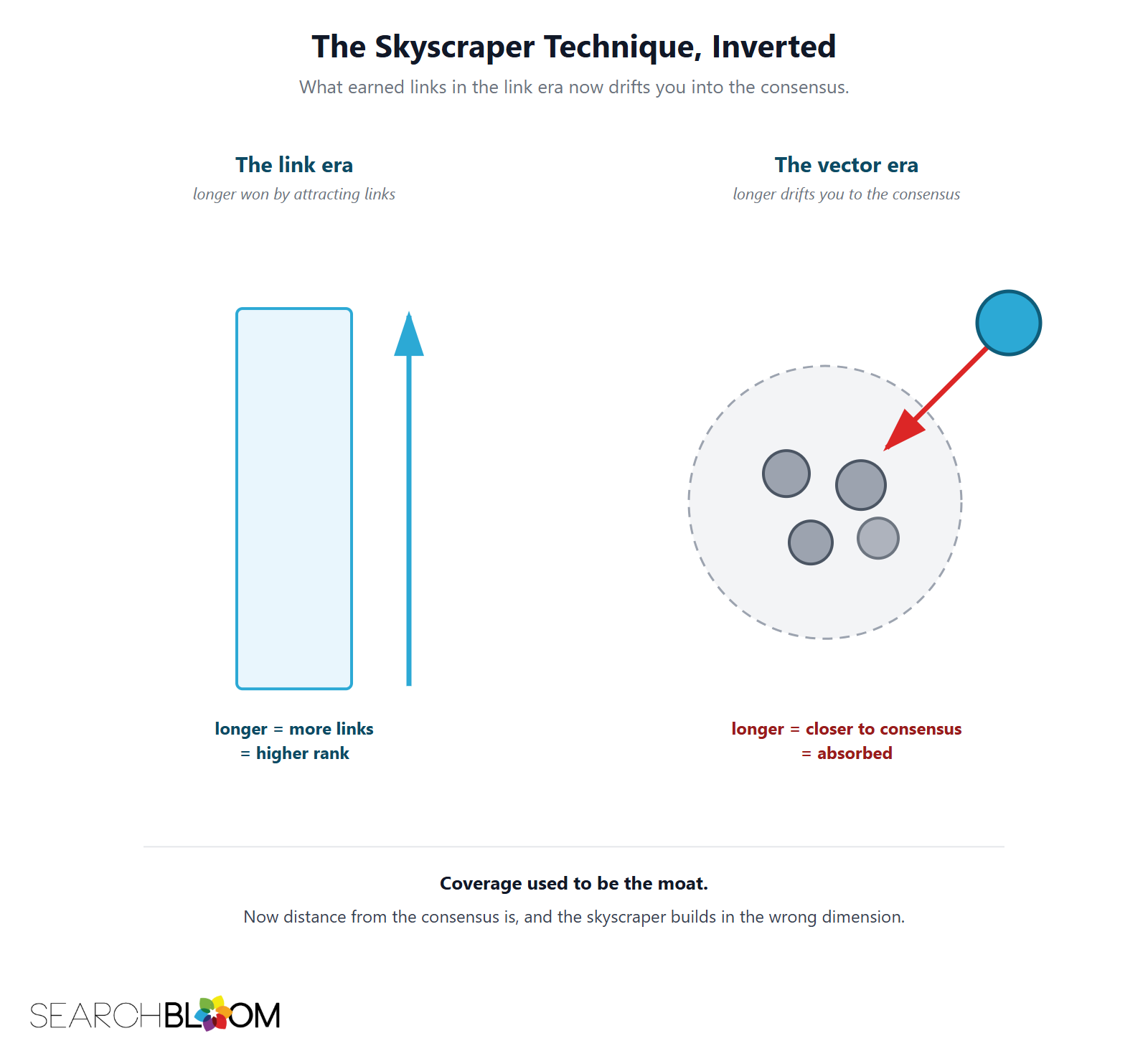
Why the skyscraper worked, and then inverted
The skyscraper technique said: find the best page on a topic, then build something longer and more complete. In the link era it worked, because comprehensiveness signaled effort, attracted backlinks, and backlinks drove rankings. The strategy optimized for coverage, and coverage was rewarded. Vector retrieval changed the reward. Now the same comprehensiveness that earned links pulls your page vector into the consensus center, where it is least likely to be the cited source. The technique did not get less popular. It got inverted.
Longer is now a liability, not a moat
Building the longest page no longer builds a moat, because length and differentiation are different axes and only one of them earns AI citation. A competitor with a shorter, sharper page sitting in open vector space beats your exhaustive guide for the citation, even though yours covers more ground. The moat is distance from the consensus, not size, and the skyscraper builds in the wrong dimension.
What Vector Dilution is not
It gets confused with every other quality idea in SEO, so it is worth drawing the borders, because the fix is different for each.

- It is not an E-E-A-T problem. E-E-A-T is the framework in Google's Search Quality Rater Guidelines, and Google states plainly that rater data is not used directly in ranking. E-E-A-T is an evaluation lens, the "who." Vector Dilution is a geometry problem, the "where," and a perfectly trustworthy, experienced author can still publish a diluted page.
- It is not a Helpful Content problem. Google's people-first guidance is now folded into core ranking; the standalone Helpful Content system was retired in 2024. It is a quality bar, not a measure of distance from the consensus. A page can be genuinely helpful and still be diluted.
- It is not a depth deficit. This is the one most teams get backwards. Depth is not the cure for dilution; past the point of coverage, depth is the cause of it. Comprehensiveness and differentiation pull in opposite directions, and "go deeper" usually means "go wider," which dilutes.
- It is not low topical authority. Topical authority is a site-level, entity-consistency signal. Vector Dilution is a single page averaging itself to the center, and it happens on the highest-authority sites constantly, often worse, because authoritative sites write the most comprehensive pages.
Early warning signs you are diluting a page
You can often catch Vector Dilution before you score it, from the editorial signals alone.
The brief only ever grows
If the outline for a page keeps acquiring sections, every stakeholder adding the angle they care about, the page is drifting toward the center one addition at a time. A brief that only grows is a dilution machine. The healthy signal is a brief that cuts as often as it adds.
You cannot state the one distinct thing
Ask the writer, or yourself: in one sentence, what does this page say that no ranking page says. If the answer is a list of topics rather than a distinct claim, the page has coverage but no shift, which is the precondition for dilution. A page that cannot name its distinction usually does not have one.
The page is becoming the "ultimate guide"
The moment a page is retitled or rescoped as the complete, ultimate, or definitive guide to a broad topic, it has committed to breadth, and breadth is the cause. Ambition toward completeness is the most common and most invisible driver of dilution, because it feels like quality while it quietly erases differentiation.
How to diagnose Vector Dilution
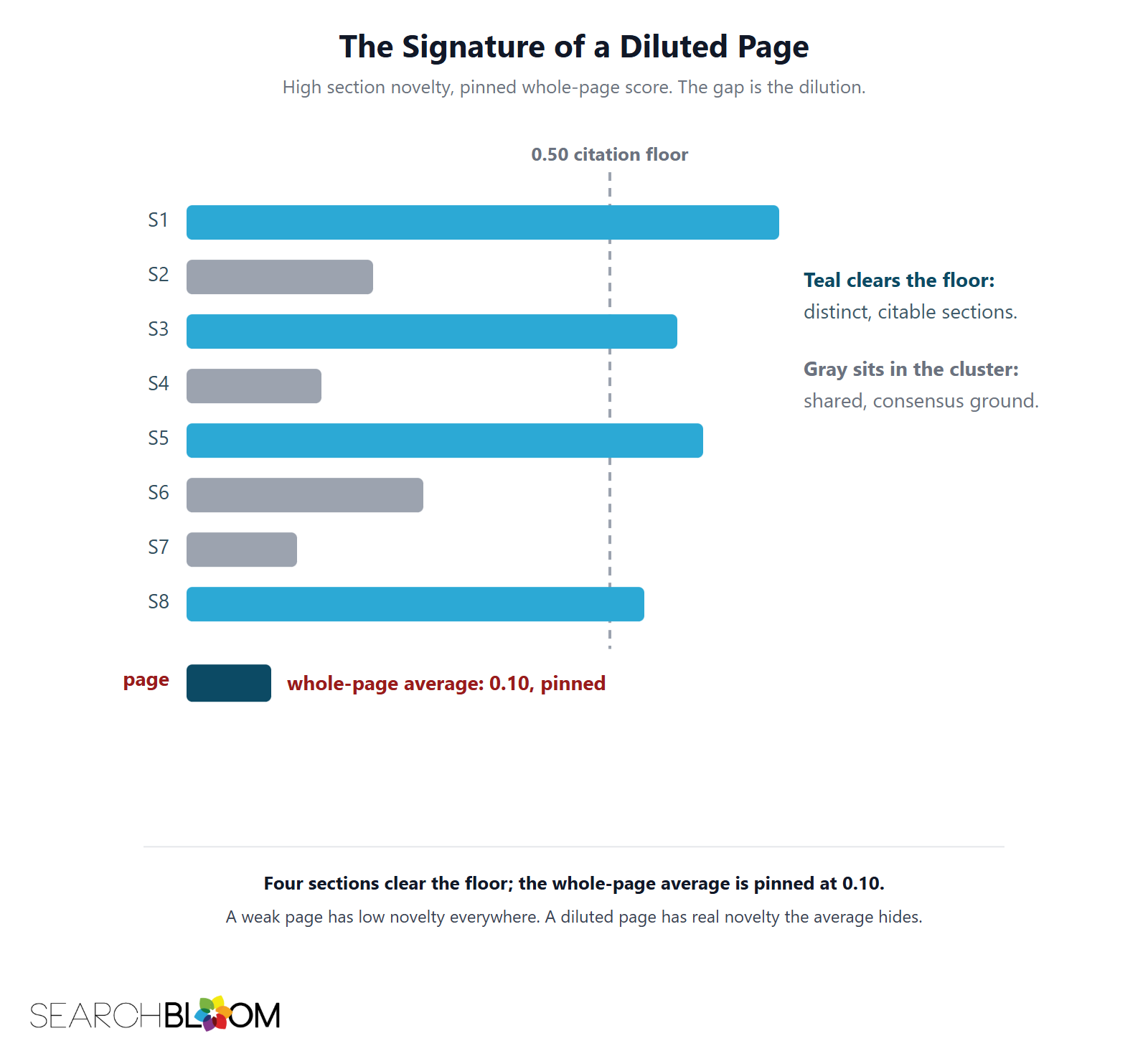
The signature: high passage novelty, pinned whole-page score
Vector Dilution has a specific, recognizable signature. When you score a page against its live ranking set, you see several sections with genuinely high novelty and a whole-page score stuck near the floor at the same time. That gap, distinct passages plus a pinned document score, is the diagnosis. A page that is simply weak shows low novelty everywhere. A diluted page shows real novelty that the average is hiding.
Step by step, how to measure it
Capture the live top ten organic results for your target query. Score your page's whole-page vector against that set, which gives the document-level differentiation. Then score each of your page's sections against the same set, which gives the per-section novelty. If the per-section view surfaces several distinct sections while the whole-page score sits near the floor, you have measured Vector Dilution directly. The Information Gain Score guide walks through the exact computation.
The thresholds to watch
The whole-page floor is around 0.50: below it, the document reads as consensus. A useful dilution flag is a page with five or more distinct sections whose whole-page score still sits well under that floor. The wider the gap between the count of distinct sections and the document score, the more dilution is at work, and the more a structural fix, rather than a writing fix, is called for.
What the score cannot tell you
The whole-page score cannot tell distinct ground from absent ground, which is exactly why it is the wrong headline. Two pages can score the same 0.09 while one is a thin rewrite of the SERP and the other is a dense pillar with eight original sections buried in shared bulk. The document number treats them identically. Only the per-section view separates them, which is why the distinct-section count, not the whole-page score, is the metric to manage.
A worked measurement walkthrough
Here is the diagnosis end to end, with the shape of the numbers you should expect.
Step 1: capture the field and score the document
Take your target query, capture the top ten organic URLs, and score your page's whole-page vector against that set. Suppose it returns a whole-page score of 0.10, well under the 0.50 floor. On its own that number says only "consensus," and most teams stop here and conclude the page is weak.
Step 2: score the sections, not just the page
Now score each of your page's sections against the same set. Suppose seven of forty sections come back above the novelty floor while the rest sit in the cluster. That is the diagnostic moment: a 0.10 document score with seven distinct sections is not a weak page, it is a diluted one. The same 0.10 with zero distinct sections would be a genuinely weak page. The document number cannot tell those two cases apart; the section view can.
Step 3: read the gap and choose the fix
The gap between the distinct-section count and the pinned document score is the size of the dilution. Seven distinct sections hidden under a 0.10 average means the gain exists and the structure is burying it, so the fix is structural, not more writing. Re-score after the change against the same captured field, so the delta is real and not an artifact of a different SERP on a different day.
How to reverse it
Vector Dilution has two fixes. The right one depends on whether the page covers many topics or one.
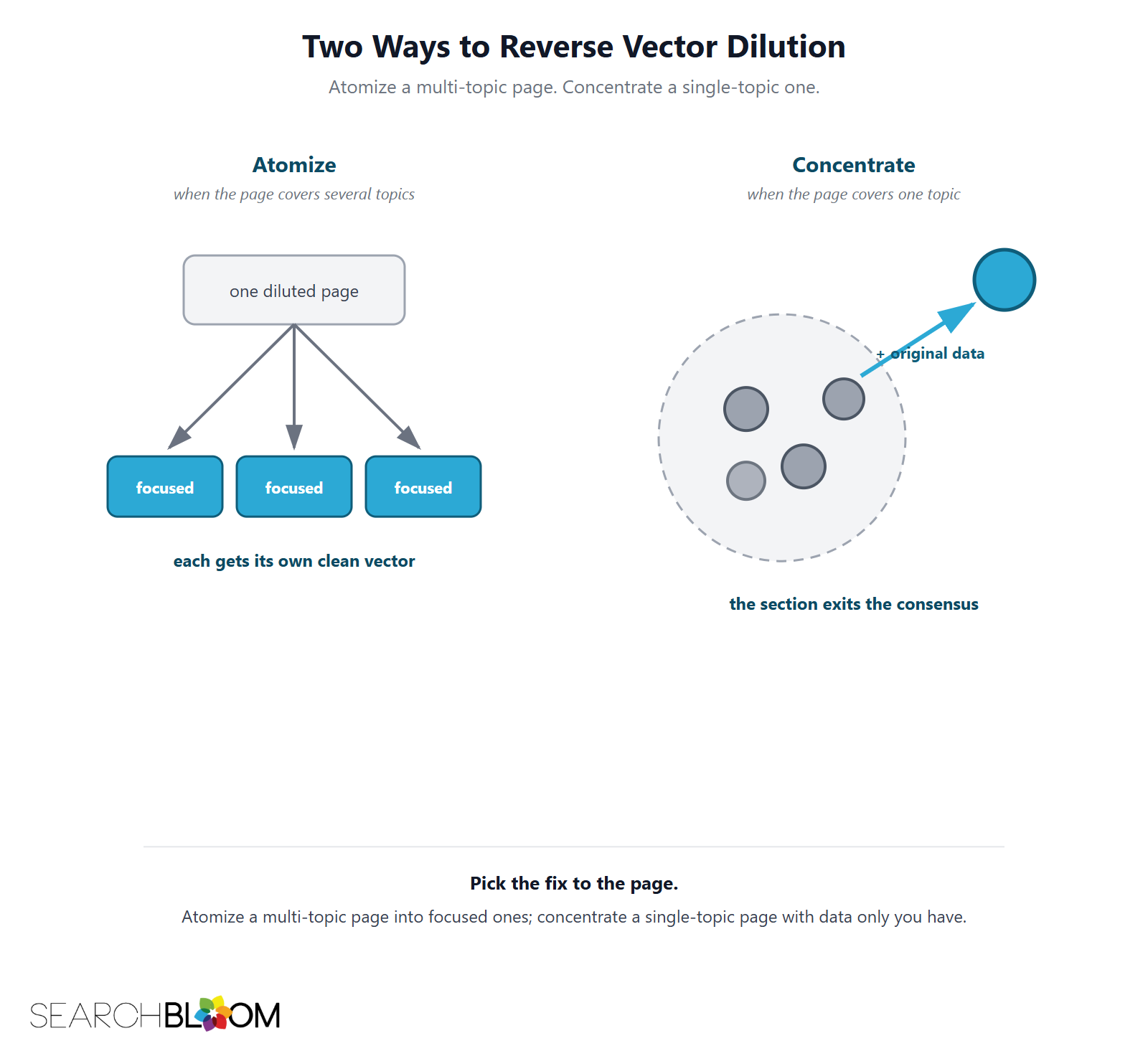
Atomize, when the page spans several distinct topics
If the page sprawls across genuinely separate topics, split it into focused pages, one topic each, each dense enough to differentiate on its own. A cluster of sharp pages beats one diluted mega-page, because each page gets its own clean vector in its own region of open space instead of contributing to one muddy average. Atomizing also gives each topic its own retrievable URL for the query fan-out, which a single mega-page cannot do.
Concentrate the evidence, when the page is one topic but reads as consensus
If the page is genuinely about one topic but still sits at the center, the fix is not to cut and not to widen. It is to make each section carry something only you have: a proprietary number, a first-hand result, a named framework, a primary-source reading. Concentrated, uncopyable substance is what pushes a section's vector out of the cluster. You are not changing what the page is about. You are changing whether each section says anything the corpus does not already contain.
The decision: atomize or concentrate
Ask one question: does the page cover one topic or several? If several, atomize, because no amount of concentration rescues a vector that is the average of unrelated regions. If one, concentrate, because splitting a single-topic page just creates thin fragments. The failure mode to avoid is doing neither and instead adding more coverage, which is the instinct that caused the dilution and the one move guaranteed to deepen it.
The wrong move, restated because it is the default
The reflex when a page underperforms is to add to it. Resist it. Adding general coverage to a diluted page is pouring water on a drowning page. Every team does it, because adding feels like effort and cutting or splitting feels like loss. The geometry does not care how it feels. More shared coverage is more weight toward the center, every time.
How to prevent Vector Dilution before you publish
Reversing dilution is more expensive than never creating it. Three habits keep a page out of the center from the start.
Brief for distinction, not coverage
The standard content brief lists every subtopic to cover. Add one more line that outranks the rest: what will this page say that no ranking page says. If the writer cannot answer, the page has no reason to exist yet, and adding coverage will not give it one. A brief that names the intended distinct ground produces a shifted page; a brief that only lists subtopics produces a centered one.
Cap the shared ground
Shared coverage is the cost of being retrievable, so you cannot remove it entirely, but you can cap it. Decide how many consensus sections the page needs to be credible, include those, and stop. Every shared section beyond the minimum is pure weight toward the center with no offsetting gain. The goal is the smallest amount of consensus that keeps you in the conversation, plus the largest amount of distinct ground you can defend.
Score the draft before it goes live
Measure the draft against the live ranking set before publishing, not months later when it underperforms. If the whole-page score is pinned while only a few sections are distinct, you are about to publish a diluted page, and the cheapest moment to fix it is before it exists. Make the score a publish gate for priority pages, the way you would a spelling check.
Common mistakes when reversing it
The fix is straightforward in principle and easy to get wrong in practice. Three errors recur.
Cutting the distinct sections by accident
When a team trims a bloated page, it often cuts the short, strange, off-query sections first, because they look like tangents. Those are frequently the distinct ones, the only sections pulling the page away from the center. Trim the redundant consensus sections instead, and protect anything that scores as novel, even if it reads as a detour.
Atomizing a single-topic page into thin fragments
Atomization is the right fix for a multi-topic page and the wrong fix for a single-topic one. Split a focused page and you get several thin pages that each lack the substance to differentiate, trading one diluted page for several absorbed ones. Atomize only when the page genuinely spans separate topics; otherwise concentrate.
Concentrating when you should atomize
The opposite error: pouring first-party data into a page that is really three topics wearing one URL. No amount of concentration rescues a vector that is the average of unrelated regions, because the regions pull in different directions and the center holds. If the page covers separate topics, split first, then concentrate each piece.
Vector Dilution by page type
The mechanism is universal, but where it bites depends on the page.

Blog and editorial pages
Editorial pages dilute through topic creep and the comprehensive-guide brief. The fix is usually concentration: most blog posts are nominally about one topic and just need each section to carry distinct substance rather than the consensus restatement. The pillar-and-spin-off pattern, where a broad guide spawns focused deep-dives, is atomization applied to editorial.
Service and product pages
Service pages dilute when they try to be everything to everyone, listing every sub-service and use case on one page. That averages across distinct buyer intents. Atomizing into focused service pages, each owning one intent, restores differentiation and matches how the fan-out retrieves intent-specific answers.
Category and hub pages
Category pages are diluted by design: they aggregate. The move is not to differentiate the category vector itself, which cannot escape the center, but to ensure the distinct gain lives on the focused pages beneath it and that the hub routes to them clearly. Treat the hub as navigation, not as the page expected to win citations.
Managing Vector Dilution over time
Dilution is not only a publish-time problem. A page that launches distinct can dilute later without a single edit on your side.
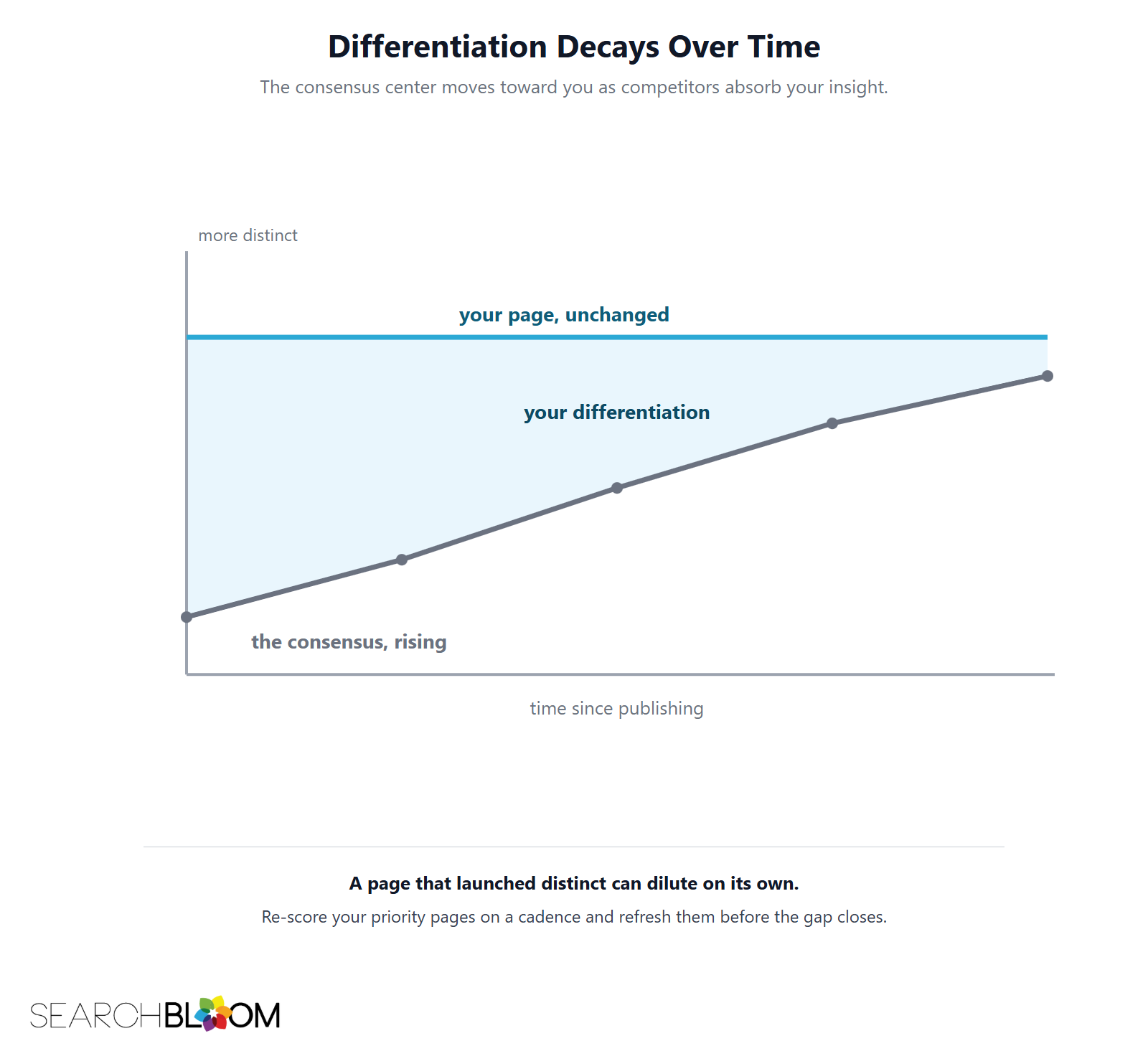
The consensus center moves toward you
When you publish something genuinely new, competitors absorb it. Each one that adopts your angle moves the consensus center closer to where you were, shrinking your distance from it. This is Gain Decay, and its end state is dilution: a page that was shifted slowly becomes a page that sits at the center, because the center came to it. Your vector did not move. The field did.
Re-score on a cadence, not once
Because the field moves, differentiation has to be monitored, not set and forgotten. Re-score priority pages against the live ranking set on a cadence, quarterly for competitive topics, and watch the distinct-section count rather than the whole-page score. When the count falls, the page is diluting as the corpus catches up, and it is time to add new distinct ground or route the insight into a new owned page before the distance closes entirely.
Vector Dilution and the rest of the framework
Vector Shift is the inverse move
If Vector Dilution is the drift in, Vector Shift is the deliberate move out. Managing a page is choosing shift over dilution on every edit. The two concepts are one axis, and naming both ends of it is what makes the axis actionable rather than abstract.
Gain Decay is the time dimension
Vector Dilution is a snapshot failure: the page sits at the center now. Gain Decay is the same loss over time, as competitors absorb your distinct ground and the center moves toward you. A page can launch shifted and decay into dilution as the corpus catches up. Both are reasons to manage differentiation as a position, not a one-time achievement.
IGD and IGS are the measures
Information Gain Density counts your distinct sections; the Information Gain Score measures your whole-page distance from the consensus. Vector Dilution is what you are looking at when IGD is healthy but IGS is pinned. The three concepts are the diagnosis, the measure, and the geometry of the same underlying thing: whether your page says something the ranking set does not.
Frequently asked questions
Is Vector Dilution a Google ranking factor?
No, and that is the wrong frame. Vector Dilution is a property of how embeddings represent a multi-topic page, which affects retrieval and AI citation across every vector-based system, not a named factor in any one algorithm. It describes a geometry that is true wherever pages are embedded as single vectors.
Does adding an FAQ section cause Vector Dilution?
It can. An FAQ that restates the consensus answer adds weight toward the center. An FAQ whose answers carry distinct, first-party substance does not. The format is neutral; the content decides whether it shifts or dilutes.
Can a short page be diluted?
Less easily, but yes, if it is a thin restatement of the consensus across a few subtopics. Length is not the cause; covering shared ground is. Short pages are simply less likely to sprawl across many shared subtopics.
How is this different from keyword cannibalization?
Cannibalization is two of your pages competing for one query. Vector Dilution is one page averaging itself out of distinctiveness. They can co-occur, but the fix differs: cannibalization is solved by consolidation, while dilution is often solved by the opposite, atomization.
If I atomize, will the smaller pages be too thin?
Only if the original page had no distinct ground to begin with. A diluted page hides distinct sections; atomizing surfaces them as the cores of focused pages. If splitting produces only thin fragments, the real problem was absent gain, not dilution.
Does Vector Dilution apply to AI answer engines or just Google?
Both, and it matters more for AI answer engines, because they synthesize across multiple retrieved passages and reward the source that adds something the others do not. A diluted page is the one most likely to be absorbed without attribution.
How often should I re-check a page for dilution?
Re-score priority pages on a cadence, not once at publish. Because the consensus center moves as competitors publish, a page that launched differentiated can dilute without any edit on your side. Quarterly is a reasonable default for competitive topics.
Will atomizing hurt my rankings by breaking up a strong URL?
Only if the URL was strong because of consolidated authority rather than content, which is rare for an informational page. More often the mega-page was already underperforming in AI citation precisely because it was diluted, and focused pages each rank for their own fan-out queries. Keep the strongest URL as the hub and route to the spin-offs.
Does Vector Dilution affect images and video, or only text?
The mechanism is about how content is embedded into a vector, so it applies to any modality that gets embedded, including multimodal pages. In practice the dominant signal for most pages is still text, so the text-level dilution is what you measure and manage first.
Can internal linking cause Vector Dilution?
Internal linking does not change a page's own vector, so it does not directly dilute. But linking many distinct intents into one destination encourages building one page that serves all of them, which does dilute. The link architecture and the page architecture tend to mirror each other, so a diluted hub is often a symptom of intent-merging links.
Is there an ideal number of topics per page?
One. A page should have a single primary topic and only the supporting subtopics that the topic genuinely requires. The moment a page serves a second distinct intent, its vector starts averaging across both, and the differentiation of each falls. When you find a second topic worth covering, that is a second page.
How does Vector Dilution relate to Google's information gain patent?
The patent describes scoring a document by the new information it adds relative to documents already seen. A diluted page, by definition, adds little at the whole-document level because its vector matches the consensus, so it is exactly the kind of document such a mechanism would deprioritize for marginal contribution. Vector Dilution is the geometry that makes a page score low on any marginal-information measure.
Is Vector Dilution the same as keyword stuffing or thin content?
No. Thin content has little substance; a diluted page can be deeply substantive. Keyword stuffing repeats terms; dilution is about covering many distinct subtopics. A page can be expert, original in places, and still diluted, which is what makes it harder to spot than either of those problems.
Can a homepage or a pillar page avoid Vector Dilution?
Not really, and they should not try. Hubs and pillars exist to aggregate, so their vectors sit near the center by design. The move is to let the distinct gain live on the focused pages beneath them and treat the hub as routing, not as the page expected to win citations on its own.
If I add original data to every section, can I cover many topics without diluting?
Original data helps each section individually, but if the topics are genuinely separate, the whole-page vector is still the average of distant regions and still lands in the middle. Data concentrates a single-topic page; it does not rescue a multi-topic one. If the page spans separate topics, split first, then concentrate each piece.
Does Vector Dilution apply outside of SEO?
The mechanism is general to any system that represents a document as one embedding, including internal site search, retrieval over your own corpus, and recommendation. Anywhere a multi-topic document is reduced to a single vector, its distinct parts get averaged away. SEO is simply where it is most visible and most costly.
How do I convince stakeholders to cut sections from a complete page?
Show them the gap. Score the page, surface the distinct sections and the pinned whole-page number, and the argument makes itself: the page already contains the gain, and the shared bulk is hiding it from the engines that decide citation. Cutting or splitting is not losing content; it is unburying the content that already differentiates.
Is there a tool that measures Vector Dilution directly?
Any information gain tool that reports both a whole-page score and per-section novelty measures it, because the dilution is the gap between the two. Searchbloom's Information Gain Score reports both, which is what surfaces the signature of a high-section-novelty, pinned-document-score page.
The bottom line
Vector Dilution is the cost of covering everything: a page so complete that its single vector lands in the one place guaranteed to be undifferentiated. It is the opposite of Vector Shift, it is measurable as the gap between distinct sections and a pinned whole-page score, and it is reversed by atomizing a multi-topic page or concentrating a single-topic one, never by adding more coverage. The page that wins AI citation is not the most complete one. It is the one that says something the ranking set does not, and protects that distance instead of averaging it away.
Measure your own page against its live SERP with the Information Gain Score, and read the full framework in the Information Gain SEO guide.
