
"Without a new concept, even real new data feels like new information to a person but reads as the same content to a machine, because its cosine similarity to existing content is almost perfect."
~ Cody C. Jensen, CEO & Founder, Searchbloom
Read these two sentences.
"We've seen a 400% increase in web visibility by including direct quotes from subject matter experts."
"We've seen a 4000% increase in web visibility by including direct quotes from subject matter experts across 2,789 domains."
The first is a real number we have published. The second is the first one with the volume turned up: a bigger percentage and a precise-sounding domain count bolted on. To you, the second reads as the stronger claim. More proof. More authority. New information.
To an embedding model, the two sentences are the same content. Near-identical vectors. The bigger number bought you nothing.
And it is not only bigger numbers. Swap in a different number, stack a combination of them, or reword the claim entirely. If the edit does not introduce a net new concept, you have changed nothing a machine can see.
That gap, between how new a claim feels to a person and how new it reads to a machine, is the most expensive misunderstanding in content right now. Most of what our industry calls "adding information gain" adds none. It repaints the same vector and calls it new.
Two things are worth naming. The mistake is the Novelty Illusion: your new data feels like new information. The mechanism is Cosine Camouflage: the reason a machine reads the same content anyway. The rest of this piece is those two, and what to do about them.

TL;DR
- The Novelty Illusion is believing you added information because the facts changed, when the meaning did not. A bigger number, a different number, a combination of numbers, a reworded claim: if it does not introduce a net new concept, the vector barely moves.
- Cosine Camouflage is the mechanism behind the illusion. Surface differences read as different content to a human and as the same point in vector space to a model. The differences are camouflage. The model sees through them.
- Embedding models map meaning, not facts. Change the number, keep the claim, and you keep the vector. That is why 400% and 4000% across 2,789 domains land on top of each other.
- Retrieval runs on those vectors. AI Overviews, RAG systems, and Google's neural matching pull the distinct vector, not the bigger number. Sit on the same vector as a page that already ranks and you are redundant, and redundant is invisible.
- What actually moves the vector is new meaning. A new mechanism, a foreign-domain concept, a real distinction, or first-party data that opens a dimension nobody else has. Not a louder version of the consensus.
- You can measure the gap before you publish. The Information Gain Score is the distance between your page and the pages already ranking, and a bigger number on the same claim leaves it flat.
The Novelty Illusion
People judge novelty by the facts on the surface, because we are trained to. A bigger number, a more specific count, a named source: in human writing these are the signals of a stronger argument, and they are good instincts for persuading a person. A reader who sees "4000% across 2,789 domains" thinks bigger study, more rigor, new information.
The illusion is assuming the machine grades novelty the way a person does. It does not.
The model already holds a thousand versions of "expert quotes raise visibility." Your sentence is the thousand-and-first. The percentage inside it does not change what the sentence is about, so it does not change where the sentence lands. You feel like you sharpened the claim. The model files it next to all the others.
This is why so many information-gain rewrites quietly fail. A team adds a statistic, swaps a generic example for a specific one, updates the year, and publishes the page believing it is now differentiated. It reads different to everyone in the room. It measures the same to the only reader that decides whether it gets cited.
Cosine Camouflage
The illusion has a mechanism. Why does the model ignore the number? Because an embedding model does not store facts. It maps meaning.
A sentence becomes a point in a space with hundreds or thousands of dimensions, positioned by what it is about rather than by the specific digits inside it. 400% and 4000% occupy nearly the same position: a claim that expert quotes increase visibility, stated with a magnitude. In that space, the magnitude is a rounding error. "Across 2,789 domains" adds a faint scent of methodology and nudges the point a hair. Not enough to matter.
Call it Cosine Camouflage. Surface details disguise sameness from a human eye while the cosine similarity stays pinned near 1.0. The numbers are war paint. You see a different sentence. The model measures the same one.
This is not a defect in the model. It is the model doing exactly its job. Vector similarity is what governs retrieval, so the model collapsing your two sentences into one point is a preview of what every AI answer engine will do with them. The camouflage fools the writer. It never fools the retriever.
Run It Yourself
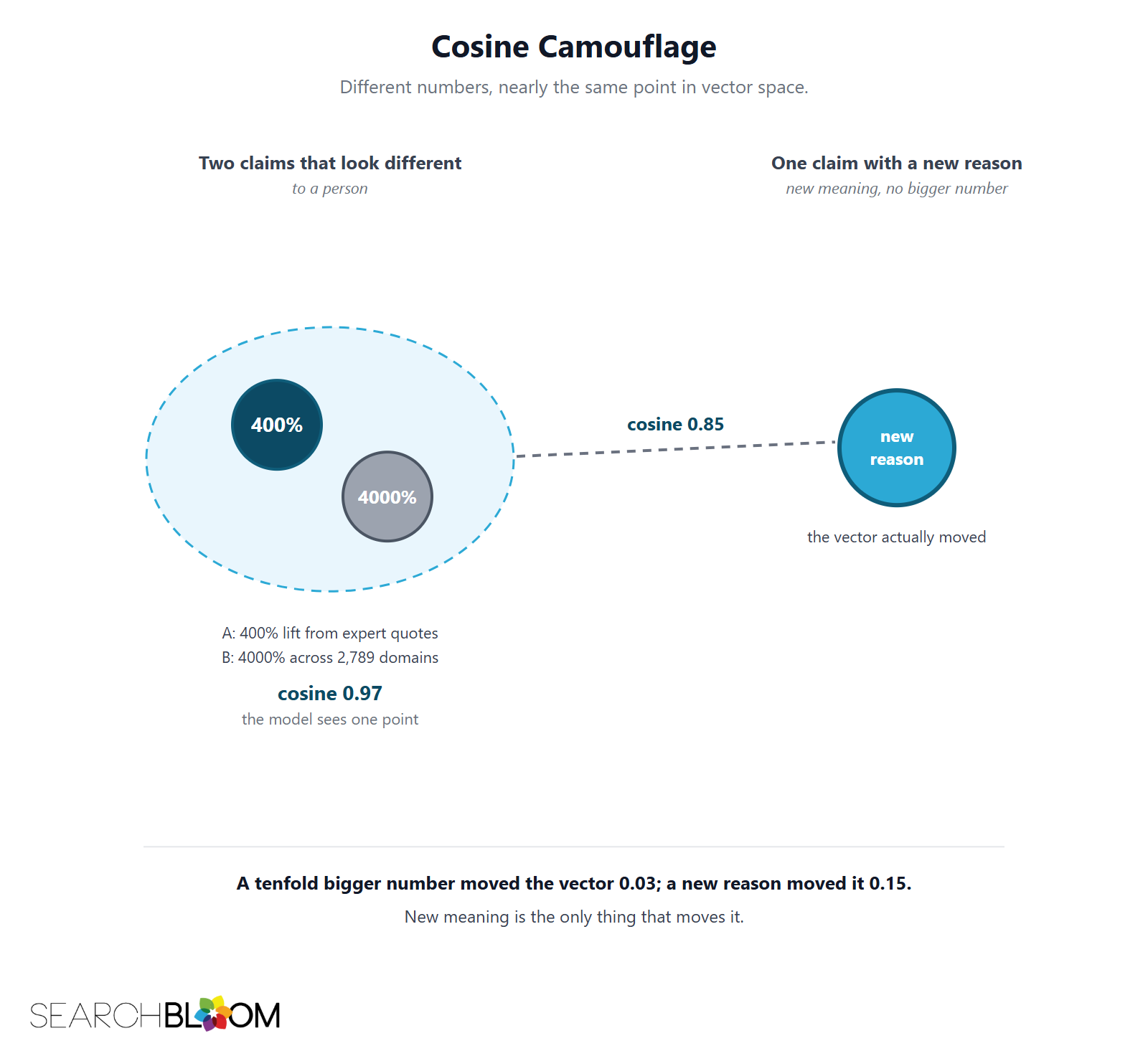
You do not have to take my word for it. We embedded all three of these sentences with a current production embedding model, Google's gemini-embedding-001, and measured the cosine similarity between them.
The two visibility claims, the 400% version and the inflated 4000%-across-2,789-domains version, came back at 0.97. To a retrieval system that is the same content. The bigger number and the domain count moved the vector by about three one-hundredths, nowhere near far enough for any answer engine to treat the second sentence as a distinct alternative to the first.
Then we measured a third sentence that changed the meaning instead of the magnitude: that quotes lift visibility because a named, attributable source hands the model a new entity to ground against, not because of the size of the percentage. Against the original it scored 0.85. One change in meaning, with no bigger number in it at all, moved the vector more than five times as far as the tenfold jump did.
That distance has a name and a formula. The Information Gain Score measures how far your page sits from the pages already ranking for your query. A bigger number on an existing claim leaves the score flat. New meaning is the only thing that moves it.
What Actually Moves the Vector
If a louder number does not move it, what does? New meaning. Four ways to add it, none of which is "make the figure bigger."
A new mechanism. Do not restate that expert quotes work. Explain why: a direct quote is a string that exists in no other page, and a named source is an entity the model can resolve and ground against. The how introduces a concept the corpus does not already saturate.
A foreign-domain frame. Borrow vocabulary from a field nobody in your search results is using, information theory, ecology, thermodynamics, and develop it in its own terms. Relevance lives in your title and headings; the body is free to travel somewhere the competing pages never go.
A real distinction. Draw a line the corpus has not drawn. The split between fact-novelty and meaning-novelty is itself a distinction almost nobody has named, which is the reason this page exists at all.
First-party data that opens a dimension. Not a bigger number on the same claim, a number on a claim no competitor can make. Your operational data differentiates because the dimension is new, not because the figure is large. How many distinct insights a page actually needs is its own question.
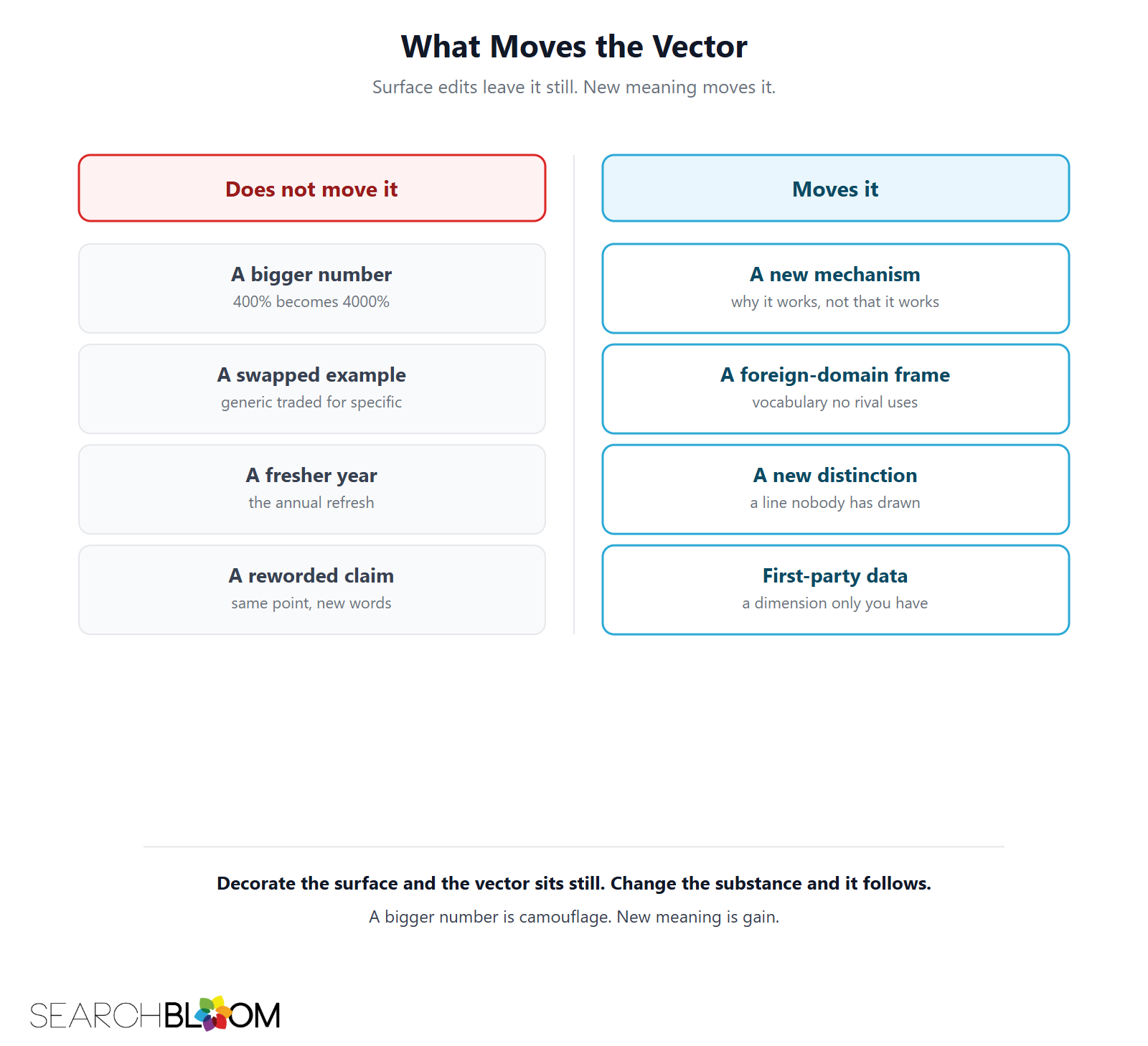
The common thread is that you cannot fake the movement. Change the substance and the vector follows. Decorate the surface and it sits still. We have written about why a vector shift cannot be engineered directly. The shift is a receipt for real work, and the Novelty Illusion is what a forged receipt looks like.
Length Is Not Density
When a team hears "information gain," the reflex is to add words. That reflex is the same illusion one level up.
Your page does not earn one vector by magic. It carries a document vector that is, roughly, the average of its passages, and that average is pinned. Everyone writing about your topic lands near the same center, so piling on more on-topic prose pulls your page toward that center, not away from it. You cannot move the document score by writing more. You move it only by saying something the center does not already hold.
That is why density is measured per passage, not per page. Information gain density is the count of distinct passages that each land in their own unoccupied region of vector space: a section carrying a mechanism, a frame, a distinction, or a dimension the ranking pages do not have. On a competitive topic, the working bar is five to seven of them.
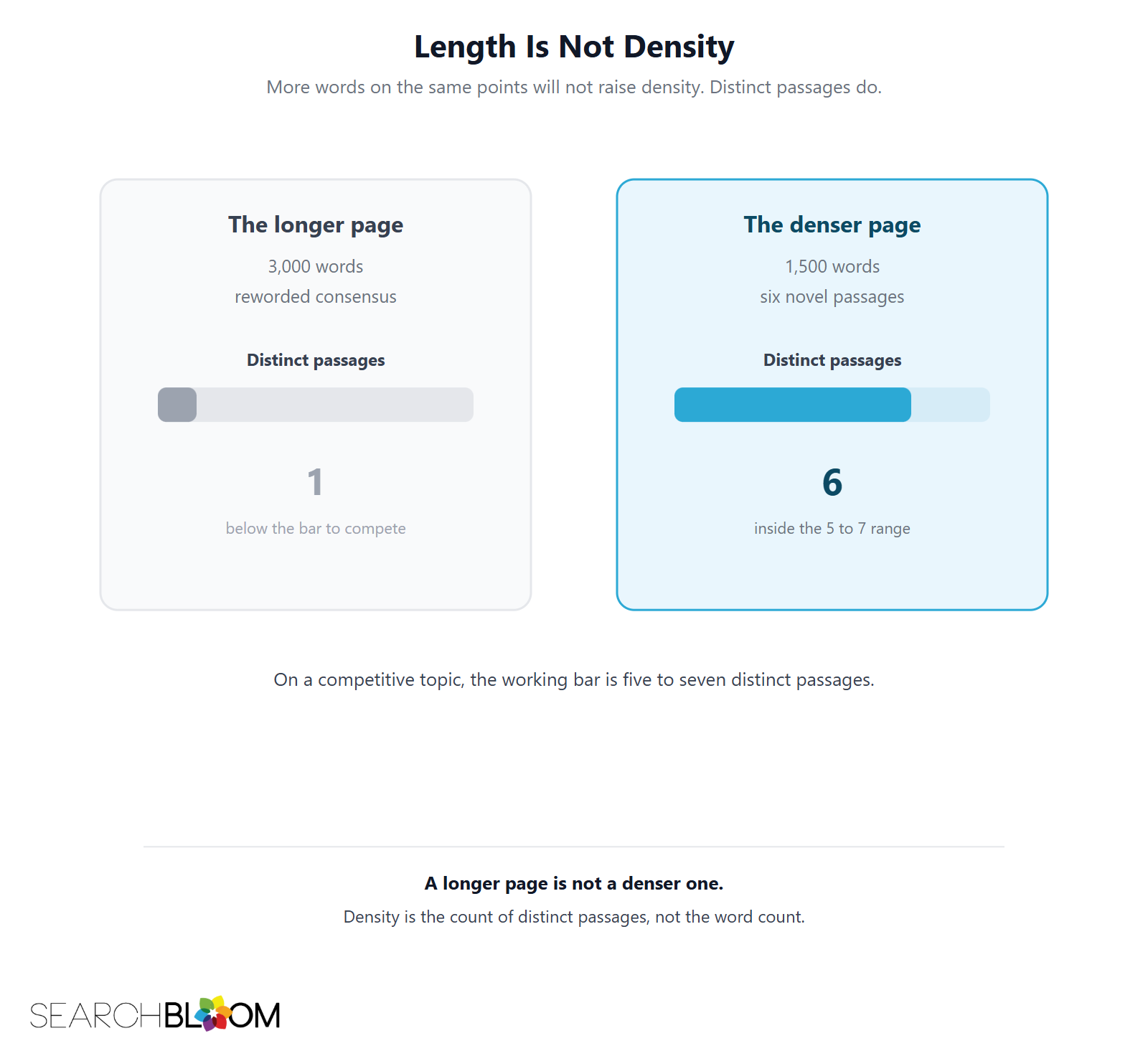
So "make it longer" is the wrong instruction. "Add another genuinely distinct passage" is the right one. A three-thousand-word page of reworded consensus has lower density than a fifteen-hundred-word page with six novel passages. Length without distinct passages is camouflage at the scale of a whole page.
The same rule holds one level up. Every article in a topic cluster is a passage in the larger corpus, and a new one earns its place only by making a point its siblings do not. This piece exists because the line it draws, between changing your facts and changing your meaning, is one our earlier work on the subject never named.
Where the Illusion Shows Up
The Novelty Illusion is easiest to catch once you know its three most common disguises.
The annual refresh. You change the year, update two or three numbers, and republish. It feels like maintenance, and it is, but it told the machine nothing new. The vector sits where it sat last year, next to every competitor who ran the same refresh.
The stat stack. You answer a worry about thin content by bolting three more statistics onto the claims already on the page. More numbers, same meaning, same vector. You did not raise the density, you raised the word count.
The padded expansion. A draft gets doubled in length, often by a model told to make it more thorough. The new paragraphs restate the existing points in fresh sentences. Length up, density down, because the same insights now sit across twice the prose.
All three feel like progress to the person doing them. All three register as nothing to the system deciding whether you get cited. The tell never changes: the facts moved and the meaning did not.
How to Catch the Illusion Before You Publish
Before you publish a gain rewrite, ask one question the surface cannot answer: did you introduce a net new concept, or only change the facts?
If you swapped 400 for 4000, added a domain count, and refreshed an example, the facts changed and no new concept arrived. You have a different-looking version of a page that already exists. If you introduced a mechanism, a frame, a distinction, or a dimension the ranking pages do not carry, the meaning changed and the vector will show it.
The honest check is the measurement, not the gut feel, because the gut feel is exactly what the camouflage exploits. Score the draft against the live top results. If the number on the same claim went up but the score did not, you fell for the Novelty Illusion, and you caught it before it cost you.
We built the Information Gain Score into a tool that does this against the page currently ranking. It is in beta right now, but the formula is fully published if you want to run the math yourself today.
Frequently Asked Questions
Does adding a statistic ever help information gain?
Yes, when the statistic introduces a claim or a dimension the ranking pages do not already hold. A first-party number on something only you can measure adds real distance. A bigger version of a number everyone already cites adds almost none. The test is whether the meaning is new, not whether the figure is large.
Are embedding models actually blind to numbers?
Not blind, but they weight meaning over magnitude. The claim a sentence makes dominates its vector; the specific digits barely move it. That is why two sentences with very different numbers and the same underlying claim sit nearly on top of each other in vector space.
Is this just duplicate content under a new name?
No. Duplicate content is a string-level match, the same words. This is meaning-level redundancy. Two pages can share zero identical sentences and still be near-duplicates in vector space because they say the same thing in different words. Retrieval cares about the second kind, and most content tools only check the first.
How do I know if my rewrite added real gain?
Measure it. Embed the page and score it against the live top results before and after the edit. If the score moved, the meaning moved. If the score is flat after you added facts, you added camouflage, not gain.
What is Cosine Camouflage?
Cosine Camouflage is surface detail, different numbers, an extra clause, a swapped example, that makes content look new to a human while its cosine similarity to existing content stays pinned near 1.0. The differences disguise sameness from a reader but not from an embedding model.
Does this mean numbers do not matter?
Numbers matter to people and to trust, and you should keep publishing real ones. They are just not what differentiates you to a retrieval system. Use numbers to persuade the human who arrives. Use new meaning to become the page the machine sends them to in the first place.
The Bottom Line
A bigger number is a better story for a person and the same story for a machine.
The Novelty Illusion costs you the moment you believe a louder claim is a new one and publish it into a result set that already holds that vector ten times over. Cosine Camouflage is why it happens: the surface fooled you, never the model. And the escape is not more impressive facts. It is new meaning, a mechanism, a frame, a distinction, or a dimension that only you can supply.
Reach for real information gain, or the machines file you as a copy and the humans you wrote it for never see you at all.
When an AI writes the page, this same collapse becomes the default rather than the mistake, which is what we call Consensus Collapse.
For the foundation underneath this piece, see our work on information gain in SEO and the math behind the Information Gain Score.
