
"Without human intervention, an LLM cannot escape its training data. Originality is the one output it was never trained to produce."
~ Cody C. Jensen, CEO & Founder, Searchbloom
Ask an AI to write a comprehensive guide on any competitive topic. What comes back is fluent, on-topic, well-organized, and confidently correct. It reads like good content. Publish it and it will earn almost nothing in AI search, and the reason is structural, not a quality problem you can prompt your way out of.
The model wrote the average of everything already written on the topic. The average is the consensus. The consensus is what the ranking pages already say. So the draft lands on top of them in vector space, a near-duplicate of the very results it was supposed to beat.
Call it Consensus Collapse: left to itself, an AI collapses toward the center of the topic, because the center is what it was built from.
TL;DR
- Consensus Collapse is what happens when AI-written content regresses to the consensus framing of a topic. Fluent, on-topic, and near-zero information gain, by construction.
- The mechanism is regression to the consensus. A model is trained on the existing corpus, so at generation time, with no new substance fed in, it produces the high-probability center of that corpus, the same consensus the top-ranking pages already occupy.
- That center has a name in this work: the SERP centroid, the average vector of the pages already ranking. An AI writes toward it by default.
- Temperature does not fix it. Turning up "creativity" samples more widely inside the training distribution; it cannot sample outside it. You get more variance, not more novelty.
- Fluency fools you. AI prose is smooth and relevant, which reads as quality, but fluency is not differentiation. It is the Novelty Illusion at industrial scale.
- It is still useful to a human, just not from your page. AI synthesizes the consensus, which helps anyone who lacks it, but that value now comes from the assistant they are already using. Human value and information gain have become the same question.
- The only escape is to feed the model what it could not have known: first-party data, a genuinely new mechanism, a frame borrowed from another field. The model recombines; you supply what is off the distribution.
- As every competitor adopts the same few models, their AI content converges on the same centroid. The flood of near-duplicates raises the citation bar, and only off-distribution substance clears it.
What Consensus Collapse Is
A current model writes content that is fluent, accurate, comprehensive, and, in vector space, indistinguishable from what already ranks. That last property is the one that decides whether you get cited, and the one nobody checks. Consensus Collapse is the name for it: the draft collapses into the consensus instead of standing apart from it.
It is not that the content is wrong. It is that it is the same. A retrieval engine does not reward a well-written restatement of what it already holds; it routes around it. The page can be the best-written version of the consensus on the internet and still add nothing a machine cannot already retrieve ten times over.
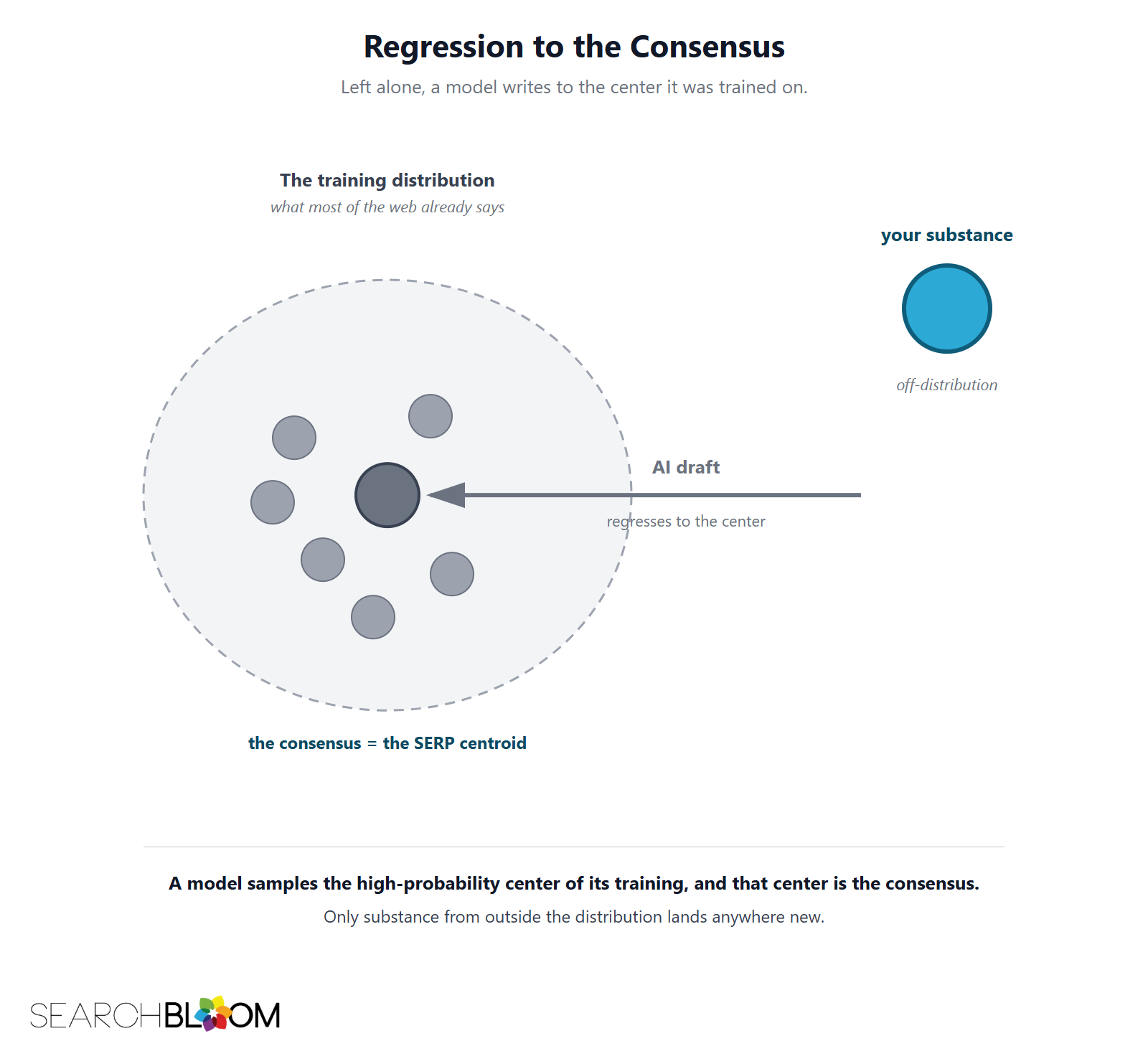
Regression to the Consensus
Here is why it happens, and why prompting harder does not change it.
A language model is trained to predict the next token across an enormous slice of the public web. Training compresses that corpus into a distribution: for any context, the model learns which continuations are common and which are rare. On a given topic, the common continuations are the consensus, because the consensus is, by definition, what most of the training text says.
When you ask the model to write, it samples from that distribution. With nothing new fed in, the high-probability path is the center of the corpus. The model is not being lazy or generic. It is doing exactly what it was built to do: reproduce the most likely text, which is the most common text, which is the consensus.
Statistics has a phrase for an estimate that pulls toward the average: regression to the mean. This is regression to the consensus. The model pulls your draft toward the middle of the topic, and the middle of the topic is the SERP centroid, the average position of the pages already ranking.
So the collapse is not a risk to manage on a bad day. It is the default behavior of the tool. Off-distribution novelty is the exception you have to force into it.
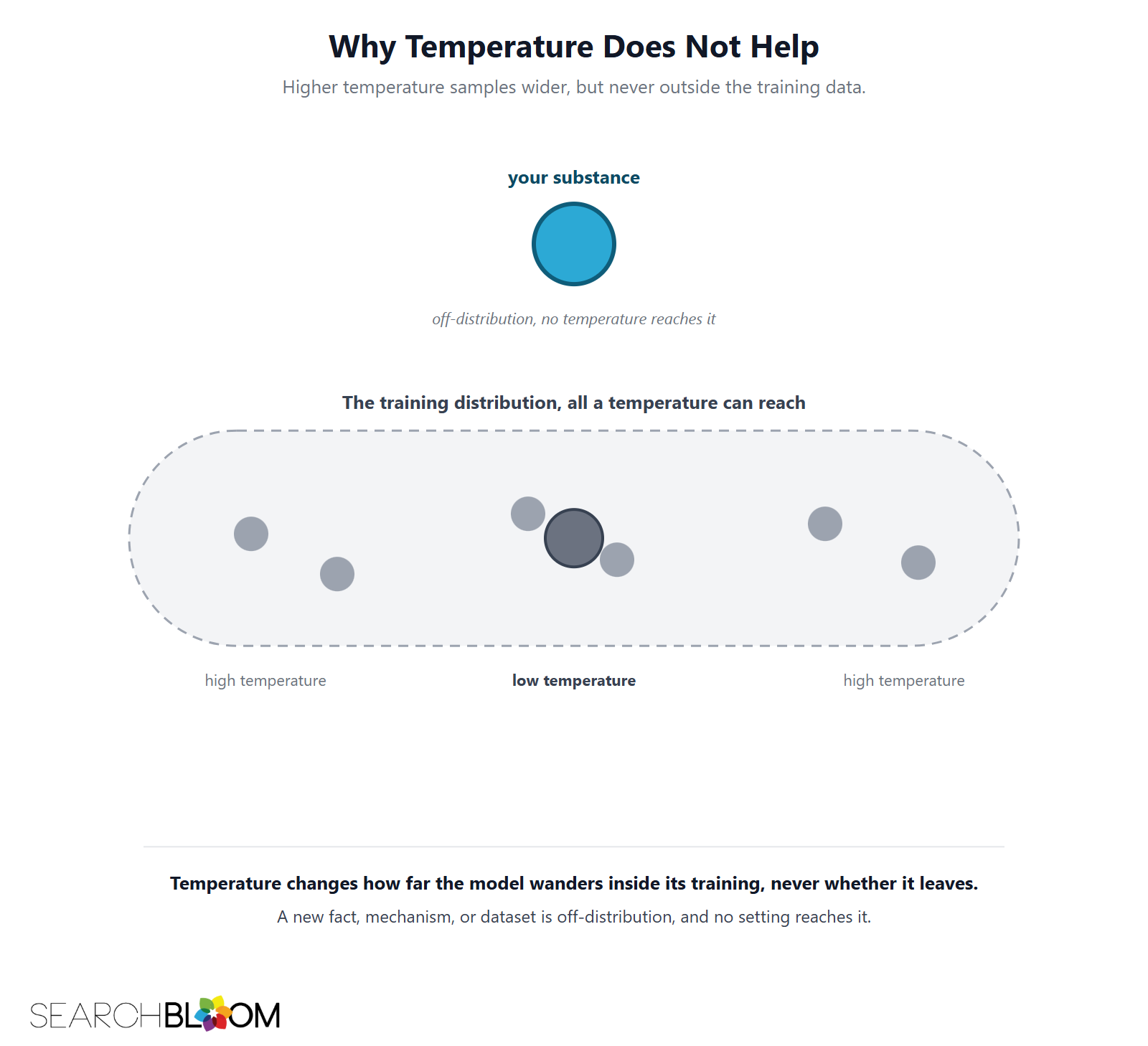
Why Turning Up the Temperature Does Not Save You
The common objection: raise the temperature, ask for a bold, contrarian, original take, and the model gets creative. It does get more varied. It does not get more novel, and the gap between those two is the whole game.
Temperature controls how far the model wanders from the single most likely next word. Higher temperature lets it pick lower-probability words, so the output looks fresher and reads less like a template. But every word it can reach is still inside the training distribution. A higher temperature explores the same corpus more adventurously. It cannot reach a fact, a mechanism, or a dataset that was never in the corpus to begin with.
So "make it more original" produces a more unusual arrangement of the consensus, not a departure from it. The vector moves a little. It does not leave the cluster. You have written a more flamboyant near-duplicate.
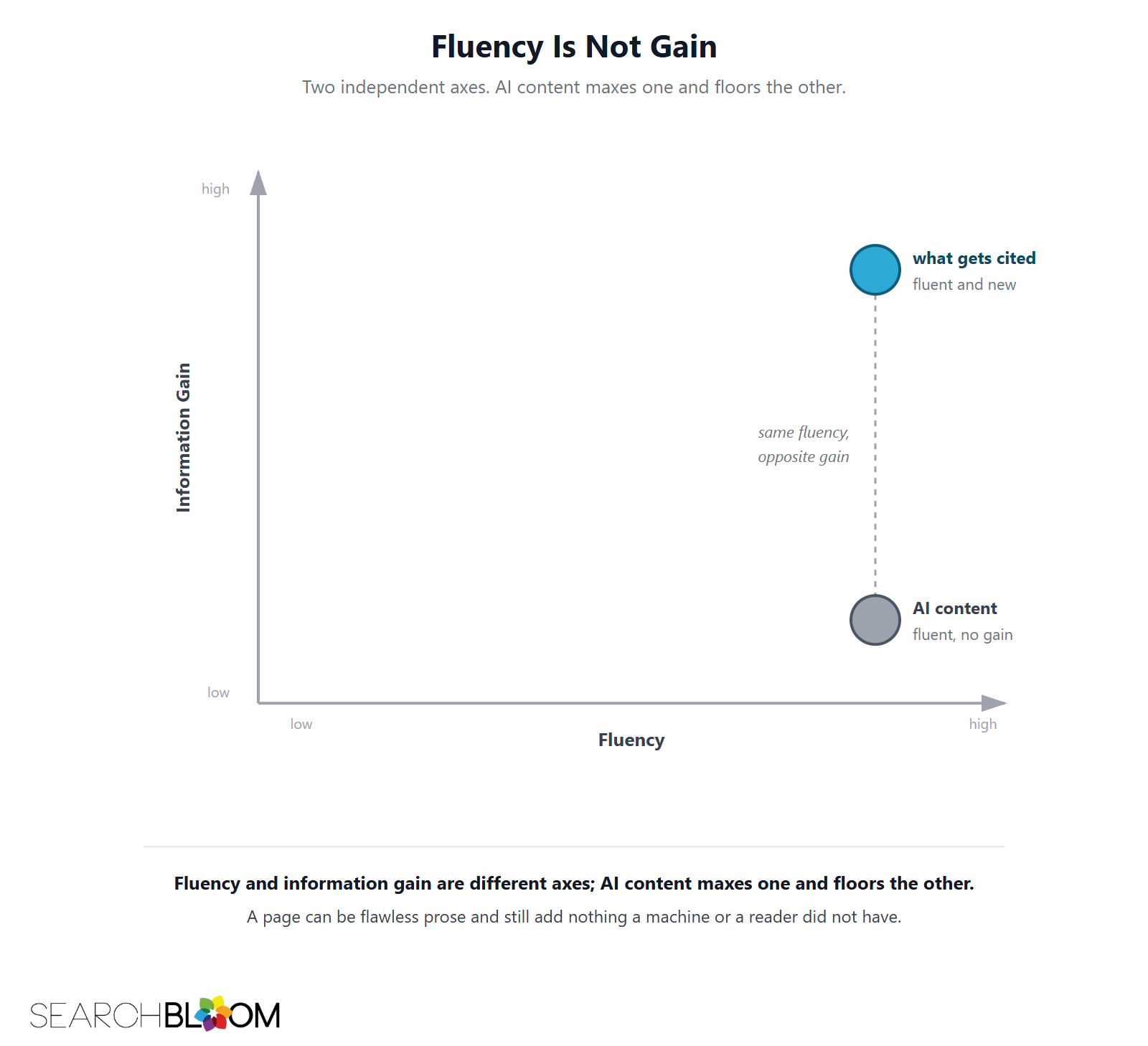
Fluency Is Not Gain
Consensus Collapse goes unnoticed because AI content is good in every way that is easy to see. It is grammatical, well-structured, on-topic, and free of obvious errors. By every surface signal, it reads as quality work, which is exactly why it gets published.
But fluency and information gain are unrelated axes. A page can be flawless prose and add nothing a retrieval engine does not already have. The Novelty Illusion describes this gap for human writers who mistake new facts for new meaning. AI is that illusion industrialized: it produces the most fluent possible restatement of the consensus, at scale, for pennies. The better the model gets at sounding right, the easier it becomes to publish content that scores nothing.
Useful to a Human, Redundant as a Page
None of this means AI content is worthless to a person. It is not. A clean synthesis of the consensus genuinely helps anyone who does not already have it: it is correct on settled topics, organized, and instant. Pretending otherwise is a weak argument, and your readers can feel it.
The problem is where that value now gets delivered. It arrives at the interface, not the page. A reader who wants the consensus asks the assistant directly; they do not go looking for your page that holds an AI's version of the same thing. So as a published page, AI-only content adds almost nothing a human did not already have in the tool open on their screen.
That is why this is not just a ranking problem. A machine skips your page when it adds nothing to what it already holds. A human now skips it for the same reason. Information gain and marginal value to a reader have become the same measurement: did you give anyone, person or model, something they could not already get for free?

The Only Escape: Feed It What It Cannot Know
If the model can only recombine its training distribution, then gain has to come from outside that distribution, and that part is the part only you can supply.
There are three sources of off-distribution substance, and a model cannot generate any of them on its own.
First-party data. Numbers from your own operations, your book of business, your own measurements, figures that exist in no training set. A model cannot synthesize a result it never saw. This is the most durable gain there is, because no competitor and no model can reproduce it.
A genuine mechanism. The reason behind a claim, worked out in your own terms, not the surface claim everyone repeats. The model has the claim a thousand times over. It does not have your derivation of why it is true.
A foreign-domain frame. Vocabulary and models borrowed from a field outside your search results, developed in their own terms. The model will not reach for information theory or ecology on a marketing topic, because those are rare in that context, and rare is exactly what it pulls away from.
The shift is the important part. The human's job is no longer to write the words; the model does that well enough. The job is to supply the substance the model could not have, then let it draft around that substance. Used that way, AI is a force multiplier on real gain. Used to produce the content itself from nothing but a prompt, it is a Consensus Collapse machine. The cleanest test is the one from information gain density: could a current model have written this passage from existing public sources? If yes, you did not add anything.

Where Consensus Collapse Shows Up
The pattern hides inside the most common AI content workflows.
The comprehensive guide. "Write a complete guide to X." X has been written a thousand times, and the model returns the average of those thousand. Maximum fluency, minimum gain.
The thoroughness expansion. "Make this more thorough." The model pads with more consensus, lowering density while raising the word count. The padded-expansion trap, now automated.
The generated FAQ. The questions are the obvious ones, answered the obvious way, because the obvious is the high-probability path. Every page in the niche generates the same set.
The programmatic run. Thousands of templated pages from one prompt, each a near-duplicate of the consensus for its slot, and of each other.
Each one feels productive. Each one lands on the centroid.

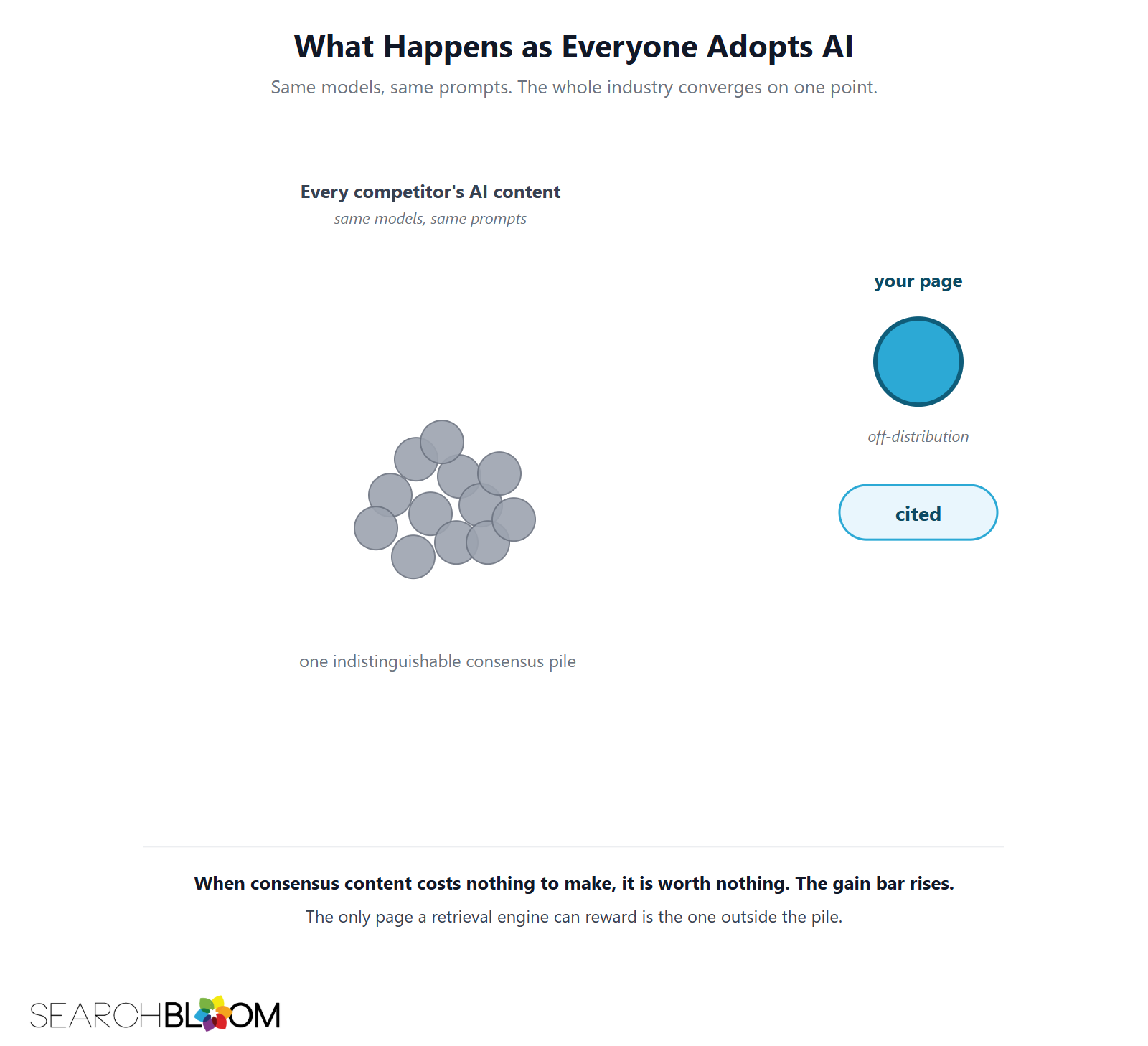
What Happens as Everyone Adopts AI
Here is the part worth sitting with. Your competitors are using the same handful of models you are. Fed the same kind of prompt on the same topic, those models regress to the same consensus. So the AI content across an entire industry is converging on one point, a growing pile of fluent, interchangeable near-duplicates.
That is a problem for everyone publishing into the pile, and an opening for anyone willing to step outside it. When the cost of consensus content falls to zero, consensus content is worth zero, and the only thing a retrieval engine can reward is the substance that is not in the pile. The gain bar does not hold still while AI floods the market. It rises.
The brands and agencies that win the next few years will not be the ones generating the most content. They will be the ones feeding the machine what it could not have known.
Frequently Asked Questions
Does this mean I should not use AI to write?
No. Use it for drafting, structure, and scale, around substance you supply. The mistake is using it to source the substance. A model is excellent at turning your data, your mechanism, and your frame into clean prose. It is structurally incapable of being the origin of the gain.
Isn't AI content still useful to my readers?
Yes, but only the kind of value a reader can already get for free. A synthesis of the consensus helps someone who lacks it, and that is real. The catch is that they can now get that synthesis straight from the assistant, so your published version adds almost nothing they did not already have. A page earns a person's attention on the same thing it earns a machine's citation: substance the model could not produce on its own.
Will a better model fix Consensus Collapse?
No, and this is the counterintuitive part. A better model is a better consensus reproducer. It gets more fluent and more convincing, not more off-distribution. If anything, a better model raises the bar, because the average it writes is now harder to tell apart from real work by eye.
What about feeding the AI my own sources or using retrieval?
That is the escape, not an exception to it. When you feed a model off-distribution material, your data, a foreign-domain source, your own measurements, the gain comes from the injected substance, and the model arranges it. The point stands: the substance is yours, the drafting is the model's.
Can I prompt my way to originality?
You can prompt for a more unusual arrangement of the consensus. You cannot prompt for substance that was never in the training data. A contrarian prompt and a high temperature widen the variance of the output; they do not move it outside the distribution.
Is AI content penalized in search?
Not as AI in itself. It simply tends to be near-duplicate, and near-duplicate is what retrieval routes around. The problem is the centroid, not the byline. Off-distribution content written with heavy AI assistance does fine; consensus content written by a human does not.
How do I tell if my draft collapsed?
Two checks. Ask whether a current model could have produced it from existing public sources; if yes, it collapsed. Or measure it directly with the Information Gain Score against the live top results: a near-duplicate scores near zero.
The Bottom Line
An AI is a mirror of everything already said. Point it at a topic and it hands back the reflection: fluent, complete, and centered exactly where the competition already sits.
Consensus Collapse is not a flaw you can prompt away, because it is the model working correctly. Regression to the consensus is simply what a model trained on the consensus does. The output will keep getting more fluent and more convincing, which makes the trap easier to fall into, not harder.
The escape has not changed and will not change. Information gain comes from substance the model could not have known. Feed it your data, your mechanism, your frame from another field, and let it draft around them. Generate the content from nothing but a prompt, and you have published the average of the internet into a search engine that already has the internet. And you have handed a reader the answer the assistant already gives them for free. Information gain was never a ranking trick. It is the only thing that makes a page worth a machine's citation or a person's time.
For the foundation underneath this piece, see our work on information gain in SEO and the Novelty Illusion that this is the machine-scale version of.
