
"Pick the right 10 to 15 pages once. They become the canary for every model upgrade after."
~ Cody C. Jensen, CEO & Founder, Searchbloom
Every measurement program has a canary. Most SEO measurement programs do not know they need one. The Anchor Set is the canary. It is the 10 to 15 priority pages you score under every embedding model upgrade. The median cross-model cosine across this set is the program-level Vector Drift signal that drives the Embedding Migration workflow. One measurement note: the cross-model cosine for a given page and model pair is deterministic, so a single computation is exact and does not need resampling. Any generation-side or citation-side metric you layer on top of the Anchor Set is probabilistic, and those should use repeated sampling and rolling averages rather than a single reading.
The Anchor Set is named in passing inside Vector Drift and used as Step 2 of the eight-step Re-Baseline workflow in The Embedding Migration. This piece is the full treatment of how to select, size, and maintain it.
If you score 50 priority pages every quarter, you spend most of your time re-scoring pages whose drift signal is the same as the page next to it. If you score zero anchor pages, you miss model swaps until the contradictions show up in stakeholder reports. The Anchor Set sits in the middle. Small enough to score on every model release. Diverse enough to surface drift before it reaches the priority set.
TL;DR
- The Anchor Set is 10 to 15 stable priority pages used as the canary for embedding model migrations. The median cross-model cosine across the set is the program-level Vector Drift signal.
- Sizing rule: 10 is the floor for a stable median. 15 is the ceiling for fast parallel embedding. Anything outside that band is either noisy or slow.
- Selection criteria: diversity across queries, stability across content (no active edits), and coverage of the program's full topical surface.
- Maintenance: re-evaluate the set every 12 months. Pages that started stable can move into active editing. New stable pages emerge.
- Use: Step 2 of The Embedding Migration eight-step Re-Baseline. Parallel-embed the set under old and new models. The median cosine drives the tier sort (Stable, Mild, Material, Breaking).
Why an Anchor Set Matters
The cost of a model migration scales with the size of the priority corpus. A 50-page priority set re-scored under a new embedding model is 50 page embeddings plus 50 peer-cluster embeddings plus a fresh centroid per query. Run that on every embedding vendor release and the cost compounds fast.
The cost of not running a migration is worse. Trend lines lie. Cross-quarter reports contradict themselves. Letter grades shift on pages that did not change. Most programs hold off on migration because the cost is too high. They miss the drift entirely and the trend lines lie anyway.
The Anchor Set splits the trade. Score 10 to 15 pages on every release. Read the signal. Decide whether to scale the work to the full priority set. The full re-baseline runs only when the anchor median drops below the Stable threshold. The anchor set does the cheap work that gates the expensive work.
What an Anchor Set Is
The Anchor Set is a fixed group of 10 to 15 stable priority pages. Across migrations the pages stay the same. Model versions change. Content stays the same. Cosine similarity between the two embeddings of the same page across two models is the per-page Vector Drift signal. Across the set, the median is the program-level signal.
Two things separate an anchor page from a priority page. First, content does not change. The page is locked editorially during the measurement window. Second, the page sits inside a topical cluster the program cares about. An anchor page is a sample of the priority set, not an arbitrary page.
Anchor pages are not the priority set. They are a representative sample. Selection is what matters. A bad sample produces a wrong signal. A good sample produces a signal you can act on without re-scoring the full priority corpus.
Selection Criteria

Diversity Across Queries
The anchor set covers the spread of the priority program. If the program tracks 50 priority queries across head, torso, and long-tail intents, the anchor set has pages from each band. Four or five from head queries, the same from torso, the same again from long-tail.
Diversity matters because embedding models behave differently across content types. A model that does well on long English explainers may shift more on short, technical FAQs. A model upgrade that looks stable on head pages may break long-tail pages. The set has to surface both.
Stability of Content
Anchor pages are pages that have not changed in the last 90 days and are not on the editorial roadmap for the next 90 days. Content stability is the second pillar.
Pages under active editing pollute the cross-model signal. Content itself moves between the two embeddings. Cosine drop becomes a mix of model change and content change. Anchor signal becomes noisy. The whole point of an anchor set is to isolate the model variable. A page that is moving fails the isolation test.
Coverage of the Topical Surface
If the program covers multiple verticals (healthcare, finance, e-commerce), the anchor set has at least two pages from each. Embedding models often behave differently across domains. A model tuned mostly on general web text may shift more on medical or legal content than on lifestyle content.
The vertical coverage rule is a working anchor point, not a universal threshold. Programs covering one vertical can collapse the rule. Programs covering more than three verticals can scale the set toward the upper end of the 10 to 15 band.
History of Stable Scoring
Where possible, anchor pages have at least 12 months of scoring history under the current model. The history is not load-bearing for the cross-model cosine itself, which only needs two embeddings. The history matters for interpretation. A page with 12 months of stable scores produces a more confident drift signal than a page with two months of history.
For new programs, the history rule relaxes. A program in its first year picks the most stable available pages and re-evaluates at 12 months when history exists.
The 10-to-15 Sizing Band
Ten is the floor. Below 10, the median across the set is dominated by individual page noise. A single outlier in a 7-page anchor set can move the median by 0.03 to 0.05 cosine, which is enough to mistier a migration. The 10-page floor brings the median into a stable band.
Fifteen is the ceiling. Above 15, the parallel embedding workload starts to scale. A 20-page anchor set is 40 embeddings per release. Pricier vendor APIs make this material on a 60-day cadence. The 15-page ceiling keeps the per-release embedding cost low enough that the anchor set runs on every release without budget friction.
Inside the 10-to-15 band, the right number depends on the program. Single-vertical programs land closer to 10. Multi-vertical programs land closer to 15. The exact count is less important than the diversity and stability of the set.
Maintenance Cadence
The anchor set is not permanent. Re-evaluate the set every 12 months. Three things drift over a year.
First, pages that started stable can move into active editing. A page that was a stable anchor in Q1 may be on the editorial roadmap for Q3. The page is no longer a clean sample. Replace it with a page that has the same query coverage and current stability.
Second, the priority program itself drifts. New queries enter the priority set. Old queries leave. The anchor set adjusts to keep the query coverage current.
Third, new stable pages emerge. A page that was actively edited last year may now be stable for the next 12 months. New stable pages are anchor candidates.
The 12-month review is short. An hour. Pull the current anchor set. Mark each page as still stable, now editing, or removed from the priority set. Replace any that fail the test. Document the change date and reason.
Common Selection Mistakes
Picking the highest-IGS pages. Top-scoring pages tend to be the most-edited. A page hit the top by being worked on. That reason for sitting at the top is what makes it a poor anchor. Pick stable pages, not winning pages.
Picking pages from one topical cluster. A set entirely inside a single topical cluster reads the cluster's drift, not the program's. The cross-model cosine is high because the cluster is uniform. The result is a stable median that masks drift in clusters the set does not cover.
Picking pages under 500 words. Short pages embed inconsistently across models. The cosine across two models on the same 200-word page can vary more than the cosine across two models on a 2000-word page. The reason is the embedding signal is denser on longer pages and the model differences average out. Anchor pages run 800 to 2500 words for most programs.
Picking only English pages on multilingual programs. A program covering five languages needs an anchor set with coverage in each language. Embedding model upgrades often shift more on non-English content than on English. An English-only anchor set misses the drift on the non-English priority set.
Setting and forgetting. A set picked in 2024 and never reviewed contains pages that have moved into active editing by 2026. The signal is noisy and nobody noticed. The 12-month review is the discipline that catches this.
How the Anchor Set Is Used
Steps 2 through 5 of The Embedding Migration eight-step Re-Baseline use the anchor set.
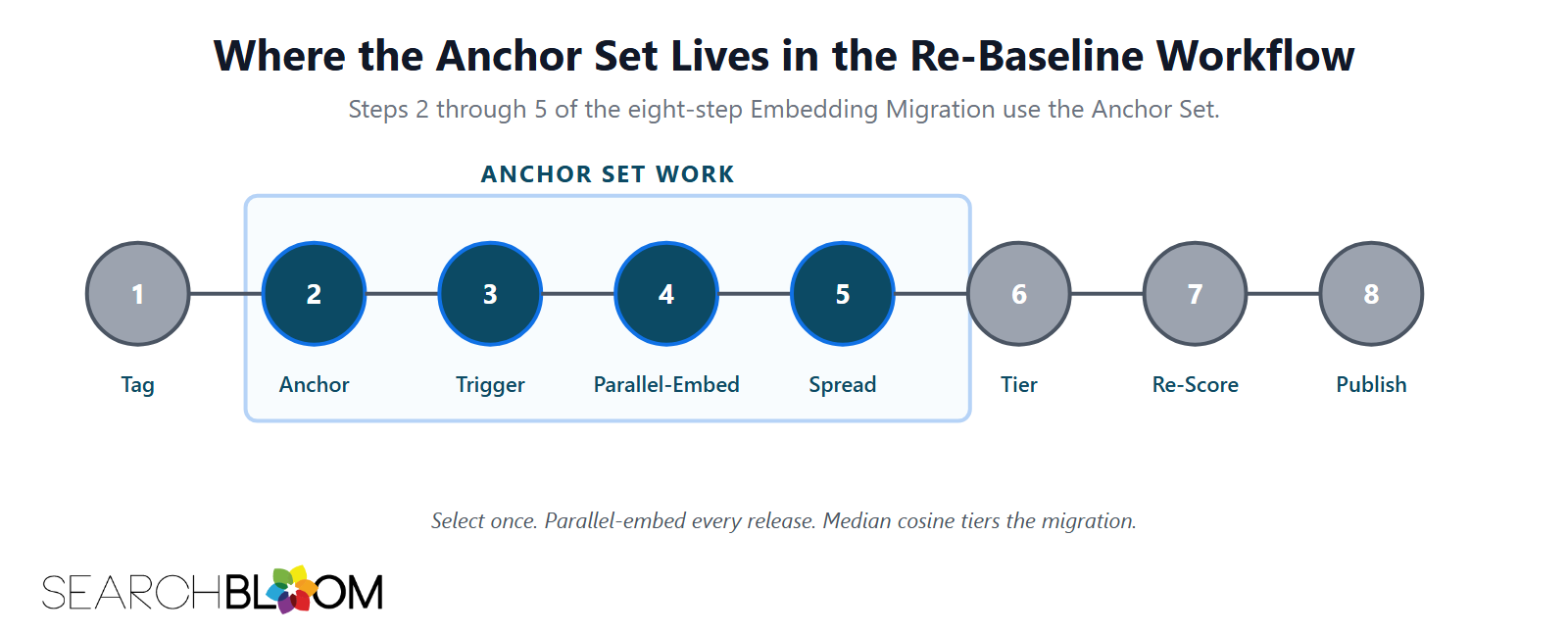
Step 2 selects the anchor set. The selection happens once per program. After the initial selection, this step is a check rather than a re-selection.
Parallel embedding runs at step 4. Each anchor page is embedded under both the outgoing and incoming models. Two vectors per page. Both stored. The cost is small. For a 15-page set with 768 to 3072-dimensional embeddings, the workload is a few seconds of API calls and a few hundred kilobytes of vector storage per release.
Step 5 computes the cross-model cosine. For each anchor page, cosine similarity between the old vector and the new vector. A score closer to 1.0 means the page is more stable across the migration. A lower number means more Vector Drift on that page.
Across the anchor set, the median is the program-level signal. That median drives the tier sort in step 6 (Stable, Mild, Material, Breaking). Tier results determine the scope of the rest of the workflow.
Five Failure Modes
No anchor set at all. Every migration starts from scratch. Selection, embedding, signal extraction all happen under release-event pressure. The migration that should take half a day takes two weeks. The team starts missing releases. By the time the team catches up, two or three model swaps have passed and trend lines are stale.
Anchor set chosen at launch and never re-evaluated. Pages that were stable at selection time have moved into active editing two years later. The set produces noisy signal. The team trusts the signal and re-baselines the wrong tier.
Anchor set too small. A 5-page set produces a noisy median. Teams tier a Mild migration as Stable and skip the re-baseline. Drift is real. Trend lines lie quietly for two quarters.
Anchor set too narrow in topical coverage. A 15-page set entirely inside one vertical reads that vertical's drift. The other verticals in the priority set drift more or less than the anchor signal suggests. The re-baseline scope is wrong on the verticals the set does not represent.
Anchor pages are also priority pages with heavy editorial activity. Pages chosen as anchors are the program's flagship pages. They get edited. Content moves. Cross-model cosine becomes a mix of model drift and content drift. Signal becomes unusable.
Where The Anchor Set Sits in the Framework
The Anchor Set is a building-block methodology inside Component 6 of Corpus Engineering: Corpus Maintenance. It is not its own framework component. It is the operational tool that makes the Embedding Migration workflow feasible at typical program cadence.
Inside MERIT, the Anchor Set sits in the Transform pillar. Transform keeps and adapts the corpus over time. As a sample of priority work, the Anchor Set is the canary that triggers Transform-pillar work at the right moments.
This methodology pairs with the per-page workflow described in The Embedding Audit. That audit is the cross-site IGS workflow that runs per page, pre-publish. The Anchor Set is the per-program canary that runs across model releases. Both use the same cosine math. Both produce different operational outputs.
Frequently Asked Questions
What is the Anchor Set?
The Anchor Set is a fixed group of 10 to 15 stable priority pages used as the canary for embedding model migrations. Pages stay the same across migrations. Models change. Cosine across the two embeddings of the same page is the per-page Vector Drift signal. Across the set, the median drives the migration tier sort.
How is the Anchor Set different from the priority set?
The priority set is the full corpus the program scores. It can run from 25 to 500 pages. The Anchor Set is a 10-to-15-page sample of the priority set, chosen for stability and diversity. It runs on every model release. The full priority set runs only when the anchor signal tiers above Stable.
Can I use the full priority set as my anchor?
You can, but the cost is unsustainable. A 50-page priority program re-scored under every embedding release at 60-to-90-day cadence runs the embedding cost up fast. The anchor set is the budget-aware sample that gates the full re-score.
How do I pick the anchor pages?
Four criteria: diversity across query types, stability of content (no active edits), coverage of the topical surface, and ideally 12 months of stable scoring history. The exact count inside the 10-to-15 band depends on the program. Single-vertical programs land closer to 10. Multi-vertical programs land closer to 15.
Why exactly 10 to 15?
Ten is the floor for a stable median. Below 10, individual page noise dominates. Fifteen is the ceiling for fast parallel embedding without budget friction. Above 15, the per-release cost starts to scale on a 60-day cadence.
How often should I re-evaluate the Anchor Set?
Every 12 months. Pages that started stable can move into active editing. The priority program drifts. New stable pages emerge. The review is short, about an hour, and prevents the set from going stale.
What word-count range works best for anchor pages?
800 to 2500 words for most programs. Short pages (under 500 words) embed inconsistently across models and add noise. Very long pages (over 5000 words) sometimes get truncated by older embedding models with limited context windows, which creates a different kind of noise.
Does the Anchor Set apply to intra-site embedding workflows?
Yes. Intra-site retrieval systems (semantic search, internal RAG) also need an anchor set. The anchor pages are a sample of the intra-site priority queries. The cadence can be slower than the cross-site cadence. Semiannual is reasonable for intra-site work on a mature site.
What if I have a multilingual program?
Cover each language with at least two anchor pages. Embedding models often shift more on non-English content than on English. An English-only anchor set misses the drift on the non-English priority set.
How is the Anchor Set used inside The Embedding Migration workflow?
Steps 2 through 5 of the eight-step Re-Baseline use the anchor set. Step 2 selects the set. Parallel embedding under both old and new models runs at step 4. Step 5 computes the cross-model cosine. The median drives the tier sort in step 6.
Where does the Anchor Set fit inside the MERIT Framework?
Inside Transform. MERIT names Transform as the pillar that keeps and adapts the corpus over time. The Anchor Set is the canary that triggers Transform-pillar work at the right moments.
The Bottom Line
The Anchor Set is the budget-aware canary that lets a measurement program survive the embedding model cadence. 10 to 15 stable pages. Parallel embedded on every release. The median cross-model cosine drives the migration tier sort.
Without the anchor set, programs either over-spend on re-scoring the full priority corpus on every release, or they skip migrations and produce trend lines that lie. With the anchor set, the team scores 10 to 15 pages on every release, reads the signal, and scales the work to match.
The methodology is small. The discipline is what matters. Pick the right pages once. Re-evaluate the set every 12 months. Run the parallel embedding on every release. The rest of The Embedding Migration workflow follows.
