
"Most SEO engagements track what entities are on the page. The ones cited by AI are tracking which entities are next to them."
~ Cody C. Jensen, CEO & Founder, Searchbloom
Vector Shift is the change you publish into your own page. Corpus Drift is what the world makes around your fixed page. Vector Drift is what the model makes underneath both. Semantic-Relationship Drift is the fourth move. Your topic stays named. Who it sits next to keeps moving.
Semantic-Relationship Drift is the third sibling drift inside Component 6 of Corpus Engineering. The parent piece names it in one line: entity relationships and salience shift over time. The Corpus Engineering vs Relevance Engineering article names it again in the three-drift list. Here we treat it in full.
An analogy makes it concrete. A single house on a quiet street. The house has not moved. The owner has not moved. Neighbors have. New ones came. Old ones left. Some moved closer. Some moved farther away. The address is the same. The value of the address is not.
TL;DR
- Semantic-Relationship Drift is the unforced shift in which entities are next to your priority topic, and how strongly. Same page. Same model. New neighbors.
- Three sub-drivers: industry shape change (banking to embedded finance to AI in banking), brand redefinition (Amazon to AWS), topical re-anchoring (SEO absorbing AEO and GEO).
- Not the same as Corpus Drift's entity sub-driver. Identity changes are name and lifecycle (Twitter to X). Relationship changes are who that entity sits next to in the corpus.
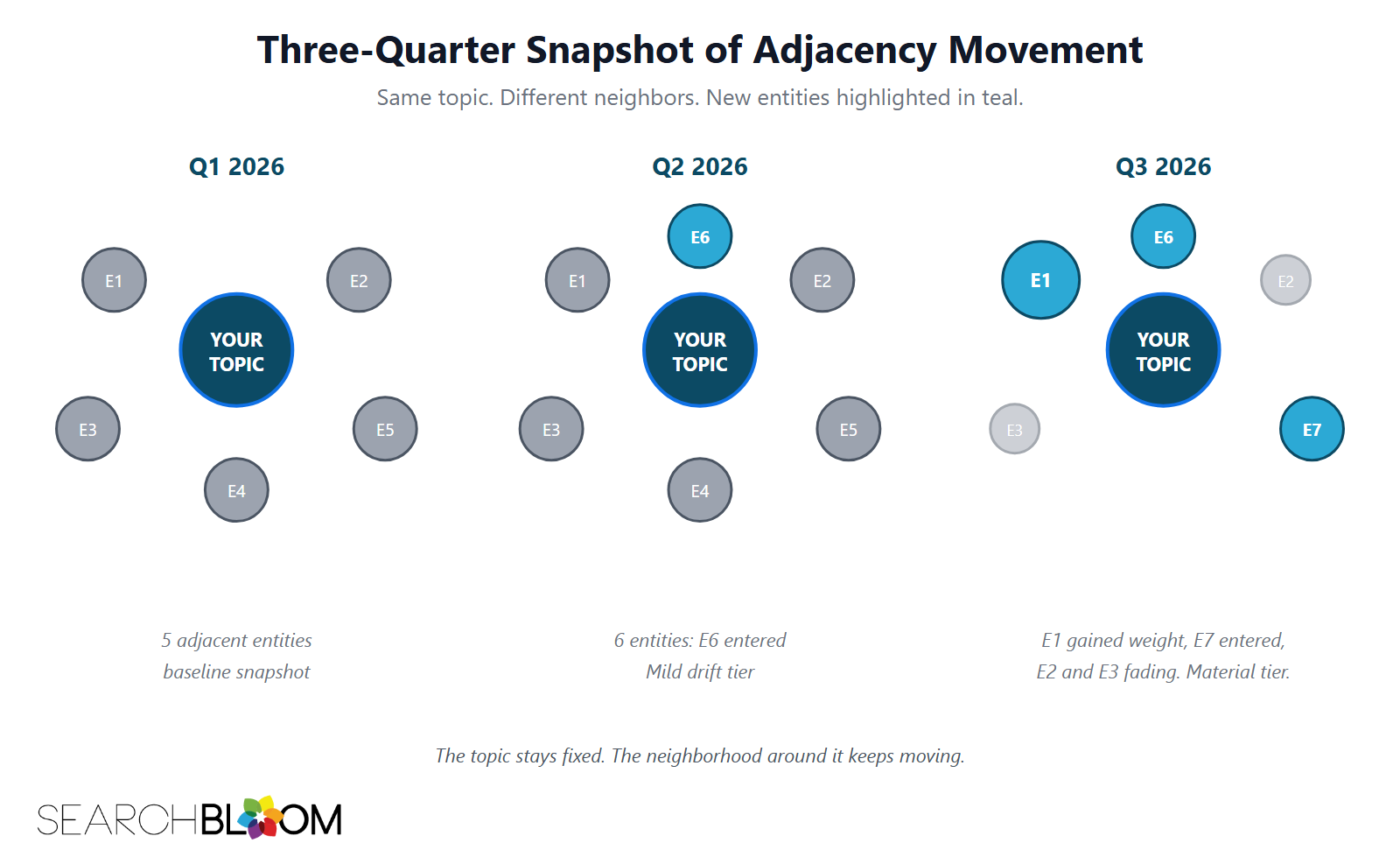
- The response is a quarterly entity-adjacency audit. Snapshot the entities next to your priority topic. Compare to last quarter. Tier the response from light edit to full rewrite.
- Framework slot: Component 6 of Corpus Engineering. Inside the Transform pillar of MERIT. Sibling to Corpus Drift and Vector Drift.
Why Semantic-Relationship Drift Matters
The corpus around your priority topic is alive. Entities arrive. Entities leave. Each one shifts in weight over time. None of this shows up in a rank report. None of it shows up in a keyword tracker. It shows up only when you look at the corpus around your content and ask which entities sit next to it now.
A scoring program that tests your page against a fixed peer set is reading a snapshot of a neighborhood that has moved. A content strategy tied to last year's adjacent entities is pointing at yesterday's graph. Both are still common. Both are wrong by design.
The effect is small in any one quarter. It is large across a year. A page that earned a B+ Information Gain Score in Q1 may earn a B-minus in Q4 on the same query, with no edit, and no change to the model. The neighborhood moved. The score followed.
What Semantic-Relationship Drift Is
The Corpus Engineering piece sets it in one sentence. Entity relationships and salience shift over time, even when each entity keeps its identity.
A working frame has two parts. Part one is the adjacency list. Which entities sit next to a given topic in the corpus that retrieval pulls from. Part two is the weight. How strongly each adjacent entity ties to the topic.
Both parts move on their own. The list can churn while the weights stay flat. The weights can flip while the list stays the same. Most quarters, both move a little. A few quarters per year, one of them moves a lot.
Semantic-Relationship Drift is unforced by design. Vector Shift is what you publish by editing your page. Corpus Drift is what the world makes around your page. Vector Drift is what the model makes under both. Semantic-Relationship Drift is what the entity graph does as the world rearranges what is near what.
The Three Sub-Drivers
Industry Shape Change
The center of an industry moves. The entities most closely tied to "banking" today are not the same set as five years ago, and not the same set as two years out. Embedded finance arrived. AI agents arrived. Each new salient entity reshuffled the order around it.
The shift is not a rename. JPMorgan is still JPMorgan. What changed is which other entities JPMorgan sits next to in the corpus around a query like "business banking." Five years ago, the closest peers were other large banks. Now the cluster pulls in embedded finance providers, AI infrastructure vendors, and digital wallets. The bank did not change. Its neighborhood did.
Industry shape change is the most common sub-driver. Most B-to-B verticals have lived through one or two of these inside a five-year window. The pace picked up after 2024 as AI took a salient spot in every adjacent industry.
Brand Redefinition
A brand's adjacent ideas shift even when the brand itself looks the same. Amazon started as a bookstore. Its adjacent entities were other booksellers, publishers, and online retailers. Amazon became the everything store. Its adjacent set added logistics, marketplace platforms, and physical retail rivals. Amazon became AWS-dominant. Now its adjacent set leads with cloud compute, generative AI infrastructure, and enterprise software.
Same brand, three different neighborhoods. Content anchored to the 2010 Amazon neighborhood is the wrong content for the 2026 Amazon query, even when every fact is still right.
Brand redefinition does not need a launch, an acquisition, or a press release. It is what the corpus does to the brand as the corpus pulls in new context. Sometimes the brand keeps up. Sometimes the brand still talks to the older self while the corpus moved on.
Topical Re-Anchoring
Topical clusters take in new dimensions and shed old ones. SEO is the working case. Inside an 18-month window from mid-2023 to late-2024, the SEO cluster pulled AEO and GEO in as adjacent disciplines. It then began to pull in Corpus Engineering and Relevance Engineering as adjacent practices. The entities sitting next to "SEO" in any retrieval system that updates its index are not the same set that sat next to it in 2022.
Topical re-anchoring is the slowest of the three. It moves on multi-year horizons in most clusters. It is also the one with the largest reach, because the re-anchored cluster is the new normal that the next decade of content gets measured against.
The signal is steady appearance of a new entity in top-10 results across a query family. When a new entity shows up in 3 of 10 top results across 8 priority queries in a vertical, the cluster has re-anchored, even with no announcement.
How Semantic-Relationship Drift Erodes Your Score
This cosine-centroid erosion describes third-party RAG engines and your own scoring program; Google's AI surfaces run on its core ranking and quality systems.
The Vector Shift piece named earned versus gamed durability. Corpus Drift and Vector Drift added landscape decay and model decay. Semantic-Relationship Drift is the fourth decay vector.
How it works is simple. Information Gain Score is the cosine distance between your page's vector and the centroid of the top-10 peers on a query. If the peers shift in their adjacent entities, the centroid moves. The centroid moves because the peers' pages re-oriented to the new neighborhood. Your page, untouched, lands in a slightly different spot against the moving centroid.
The size of the move is small in cosine terms. A single quarter of Semantic-Relationship Drift lands in the 0.02 to 0.05 band against a fresh peer centroid. Roll four quarters together and the drift can reach 0.08 to 0.15. That is enough to move a page a full letter grade, with no other cause.
The drift is invisible if you do not refresh the peer set. A scoring program that locked the top-10 at publish, and reads the page a year later, sees the page as fine against the old peers. The page is mispositioned against the current peers. Different question, different answer.
Detection: The Quarterly Adjacency Audit
The detection workflow is an entity-adjacency audit on a quarterly cycle. Three steps.
Pull the live top-10 for each priority query. Run a named-entity extraction across the body text of each page in the ten. Build the union list of entities that show up in at least 3 of the 10. This is your current adjacency list. For a more precise read, resolve each surface entity to its canonical Knowledge Graph identifier (the Wikidata QID) before you count, and build an entity-query co-occurrence matrix rather than a flat mention list. Resolution collapses aliases and disambiguates entities that share a name, so the adjacency signal reflects the entity, not the string. This entity-resolution approach follows the method in Michael King's AI Search Manual.
Snapshot the list with a date stamp. Store it in a small per-query table. Columns: entity name, mention count out of 10, and a rough weight from where the entity sits in the page (title, H2, body, footer).
Compare the snapshot to last quarter's snapshot. Note three things: which entities are new, which dropped out, and which moved in mention count. Together, the three notes give you the per-quarter drift signal.
The workflow runs in any tool that handles named-entity extraction. Screaming Frog v22 supports custom JavaScript and external API calls and can do the extraction during a crawl. A Python pipeline scales for programs tracking 50 or more priority queries. A spreadsheet with hand-keyed entities works for a small priority set.

Four Working Tiers of Semantic-Relationship Drift
| Tier | Adjacency Movement | Editorial Response |
|---|---|---|
| Stable | Fewer than 2 new or dropped per quarter, no weight flip | Note the snapshot. No edit. |
| Mild | 2 to 4 new or dropped, no weight flip | Light re-orient. Mention the new adjacent entities where natural. |
| Material | 4 to 8 new or dropped, mild weight flip | Re-orient and expand. Add a section that brings the new salient entities into the page. |
| Breaking | Over 8 new or dropped, the top adjacent entity flipped | Reconsider the page. The cluster may have re-anchored. Rewrite or reallocate. |
Tier numbers are working anchor points, not universal thresholds. The right count varies by topical cluster, query maturity, and the extractor in use. Numbers are for the audit. The tier is for the conversation.
Five Failure Modes
Stale entity pointing. A priority page points to entities the cluster has moved past. The page still reads as accurate to a human. The retrieval system finds it less relevant than peer pages that point to the current adjacent entities. Citation rate falls without a visible quality issue.
Missed adjacency expansion. A new salient entity entered the cluster three quarters back. Every peer page now points to it. Your page does not. A quarterly cycle would have caught it. Nobody ran the cycle. The page is now three quarters behind on a citable entity.
Brand-topic dilution. Your brand entity was once tied tightly to your core topic. Over time, the brand appears in nearby topics, partner posts, and press mentions on a wider range of pages. The weight to the core topic falls. Brand identity holds steady. Even so, the retrieval system grows less sure which topic the brand most strongly belongs to.
Cross-cluster spread. Your entity shows up in topical clusters where it does not belong. Bulk earned media and partner content with broad subject coverage create this. The retrieval system reads the entity as a generalist. Citation rate on the core topic falls because the entity is no longer the surest specialist for the query.
Knowledge-graph name collision. Two entities with similar names blur as the cluster fills in. A small specialist brand named close to a larger generalist brand loses retrieval signal. Entity disambiguation routes the query to the larger brand. The collision is silent. The result is a slow citation loss with no clear cause.
Where Semantic-Relationship Drift Sits in the Framework
Component 6 of Corpus Engineering: Corpus Maintenance. The component that names the time side of the practice.
Sibling to Corpus Drift, the landscape-side drift. Sibling to Vector Drift, the model-side drift. Three drifts, three causes, three cadences, one Component 6.
Each drift has its own response. Corpus Drift is handled by quarterly re-scoring against the live top-10. Vector Drift is handled by The Embedding Migration, the eight-step Re-Baseline rule. A dedicated workflow piece on the adjacency audit may follow.
Inside MERIT, Semantic-Relationship Drift sits in Transform. Transform keeps and adapts the corpus over time. It closes the gap between published substance and current relevance.
The Three-Way Drift Distinction, Now Complete
| Property | What Moves | What Caused It | Layer of the Stack |
|---|---|---|---|
| Corpus Drift | The cluster moves around your fixed page | Competitors and entities evolved | Detected, quarterly cadence |
| Vector Drift | The coordinate system rotates underneath everything | The embedding model was upgraded | Triggered, migration event |
| Semantic-Relationship Drift | The entity neighborhood around the topic re-wires | The world changed what is near what | Detected, quarterly cadence |

All three live inside Component 6 of Corpus Engineering. All three erode an IGS scoring program over time. Each one calls for its own response. Corpus Drift runs on a quarterly cycle. Vector Drift runs on a migration event. Semantic-Relationship Drift runs on a quarterly cycle on a different axis.
Programs Most at Risk
The programs most exposed to Semantic-Relationship Drift are the ones that locked their peer set and entity list at publish and never refreshed. Six-month and twelve-month review programs stack two to four quarterly drifts before anyone looks. The compounded movement is usually material.
Programs that run an Embedding Audit once before publish and never again are exposed in a different way. A pre-publish audit catches the centroid at publish. Each quarter after publish, the centroid drifts. The page sits where it was. The score against the current centroid is what matters.
Programs that refresh peers and re-pull entities every quarter catch the drift early. The cost of catching it early is the cost of running the audit. The cost of catching it late is the cost of catching up to a cluster that re-anchored without you.
Frequently Asked Questions
What is Semantic-Relationship Drift?
Semantic-Relationship Drift is the unforced shift in which entities sit next to your priority topic, and how strongly. Your page stays put. The model stays the same. What changes is the neighborhood around the topic, as the world rearranges what is near what.
How is Semantic-Relationship Drift different from Corpus Drift?
Corpus Drift covers competitor moves, entity identity and lifecycle changes (Twitter to X, product sunsets, leadership shifts), and topical coverage that grows or shrinks. Semantic-Relationship Drift covers a different axis. With the same entity identities, who sits next to whom, and how strongly. An entity can keep its identity while its neighborhood reshuffles.
How is Semantic-Relationship Drift different from Vector Drift?
Vector Drift is the model side. The embedding function changes, so the cosine math changes. Semantic-Relationship Drift is the corpus side with respect to entity relationships. The math is the same, but the entity neighborhood in the data has re-wired. Same model, same page, new neighborhood.
How often does Semantic-Relationship Drift trigger in practice?
It runs all the time, at a slower pace than Corpus Drift. A typical priority topic sees 2 to 4 new or dropped adjacent entities per quarter. Weight flips are less common. Most clusters see one full flip per year, sometimes two. Industries reshaping around AI in 2025 and 2026 have moved faster.
What is the typical size?
A single quarter of Semantic-Relationship Drift typically lands in the 0.02 to 0.05 cosine band against a fresh peer centroid. Compounded across four quarters, the drift can reach 0.08 to 0.15. Tier ranges are working anchor points, not universal cosine values.
Does this apply to intra-site embedding workflows?
Yes. Intra-site retrieval is tied to the entity set inside the site as new pages publish, internal wording evolves, and content sets grow. The cadence can be slower than the cross-site cadence. Semiannual is fine for intra-site work on a mature site.
Can the audit run inside Screaming Frog v22, or does it need Python?
Either. Screaming Frog v22 supports custom JavaScript and external API calls and can run named-entity extraction during a crawl. A Python pipeline scales better for programs tracking 50 or more priority pages on a strict cadence. A spreadsheet workflow works for a small priority set.
What is the response?
A quarterly entity-adjacency audit. Pull the top-10 for each priority query. Extract entities. Snapshot the list. Compare to last quarter. Tier the response. Stable is bookkeeping. Mild is a light re-orient. Material is re-orient plus expand. Breaking is a rewrite.
What about entity drift specifically?
Entity identity and lifecycle changes (renames, sunsets, leadership) sit inside Corpus Drift. Entity relationships and weight changes sit inside Semantic-Relationship Drift. The two cover different parts of the same broader idea. Both run on a quarterly cycle. Both produce different outputs.
Where does Semantic-Relationship Drift fit inside the MERIT Framework?
Inside Transform. MERIT names Transform as the pillar that keeps and adapts the corpus over time. Semantic-Relationship Drift is the entity-graph piece that Transform-pillar work has to deal with.
When should I worry about Semantic-Relationship Drift?
If your priority topic sits in a vertical that is reshaping (most B-to-B verticals in 2025 and 2026), the pace of meaningful adjacency change is faster than annual. Quarterly is the working default. For stable verticals, semiannual is fine. The lowest-risk case is the niche specialist topic with a stable peer set, where annual review is enough.
The Bottom Line
Semantic-Relationship Drift is the unforced shift of entity relationships and weight in the broader corpus. Vector Shift is what you publish. Corpus Drift is the landscape moving around you. Vector Drift is the math moving under both. Semantic-Relationship Drift is the neighborhood moving around your topic while the topic name stays the same.
The practice is simple. Detect on a quarterly cycle. Respond at the size of the drift. Without the practice, every Information Gain Score report is a snapshot of a neighborhood that has moved on. A page that earned a B+ at publish quietly becomes a B-minus a year later, with no edit to explain the change.
The full Corpus Maintenance sub-cluster is now complete. Corpus Drift names the landscape. Vector Drift names the math. Semantic-Relationship Drift names the relationships. The Embedding Migration is the workflow piece for Vector Drift. The other two drifts have their quarterly responses set out in their own pieces. Three causes, three cadences, one Component 6.
